文本分析和词向量
本用户指南部分概述了数学表达式中的文本分析、文本分析和 TF-IDF 词向量函数。
文本分析
analyze 函数将 Solr 分析器应用于文本字段,并返回分析器在数组中发出的标记。Solr 模式中附加到字段的任何分析器链都可以与 analyze 函数一起使用。
在下面的示例中,文本 "hello world" 使用附加到模式中 subject 字段的分析器链进行分析。subject 字段定义为字段类型 text_general,并且文本使用为 text_general 字段类型配置的分析链进行分析。
analyze("hello world", subject)当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"return-value": [
"hello",
"world"
]
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}注释文档
analyze 函数可以在 select 函数内部使用,以使用分析生成的标记注释文档。
下面的示例在 "collection1" 中执行 search。 search 函数返回的每个元组包含一个 id 和 subject。对于每个元组,select 函数选择 id 字段并在 subject 字段上调用 analyze 函数。由 subject_bigram 字段指定的分析器链配置为执行 bigram 分析。analyze 函数生成的标记将添加到每个元组的 terms 字段中。
select(search(collection1, q="*:*", fl="id, subject", sort="id asc"),
id,
analyze(subject, subject_bigram) as terms)请注意,在输出中,一个 bigram 术语数组已添加到元组中
{
"result-set": {
"docs": [
{
"terms": [
"text analysis",
"analysis example"
],
"id": "1"
},
{
"terms": [
"example number",
"number two"
],
"id": "2"
},
{
"EOF": true,
"RESPONSE_TIME": 4
}
]
}
}文本分析
cartesianProduct 函数可以与 analyze 函数结合使用,以执行广泛的文本分析。
cartesianProduct 函数将多值字段展开为元组流。当使用 analyze 函数创建多值字段时,cartesianProduct 函数会将分析后的标记展开为元组流。这允许对分析后的标记流执行分析,并使用 Zeppelin-Solr 可视化结果。
示例:短语聚合
执行短语聚合的示例用于说明结合 cartesianProduct 和 analyze 的强大功能。
在此示例中,search 表达式是在电影评论集合上执行的。搜索短语 "Man on Fire",并按分数返回前 5000 个结果。从结果中返回一个字段,即包含电影评论文本的 review_t 字段。
然后,在搜索结果上运行 cartesianProduct 函数。cartesianProduct 函数应用 analyze 函数,该函数使用附加到 text_bigrams 模式字段的分析器来分析 review_t 字段。此分析器发出在文本字段中找到的 bigram。cartesianProduct 函数将每个 bigram 展开到其自己的元组中,并将 bigram 存储在字段 term 中。
然后,使用正则表达式通过 having 函数过滤元组流,以选择长度为 12 或更大的 bigram,并过滤掉包含特定字符的 bigram。
然后,hashRollup 函数聚合 bigram,top 函数按计数发出前 10 个 bigram。
然后,Zeppelin-Solr 用于可视化前 10 个 bigram。
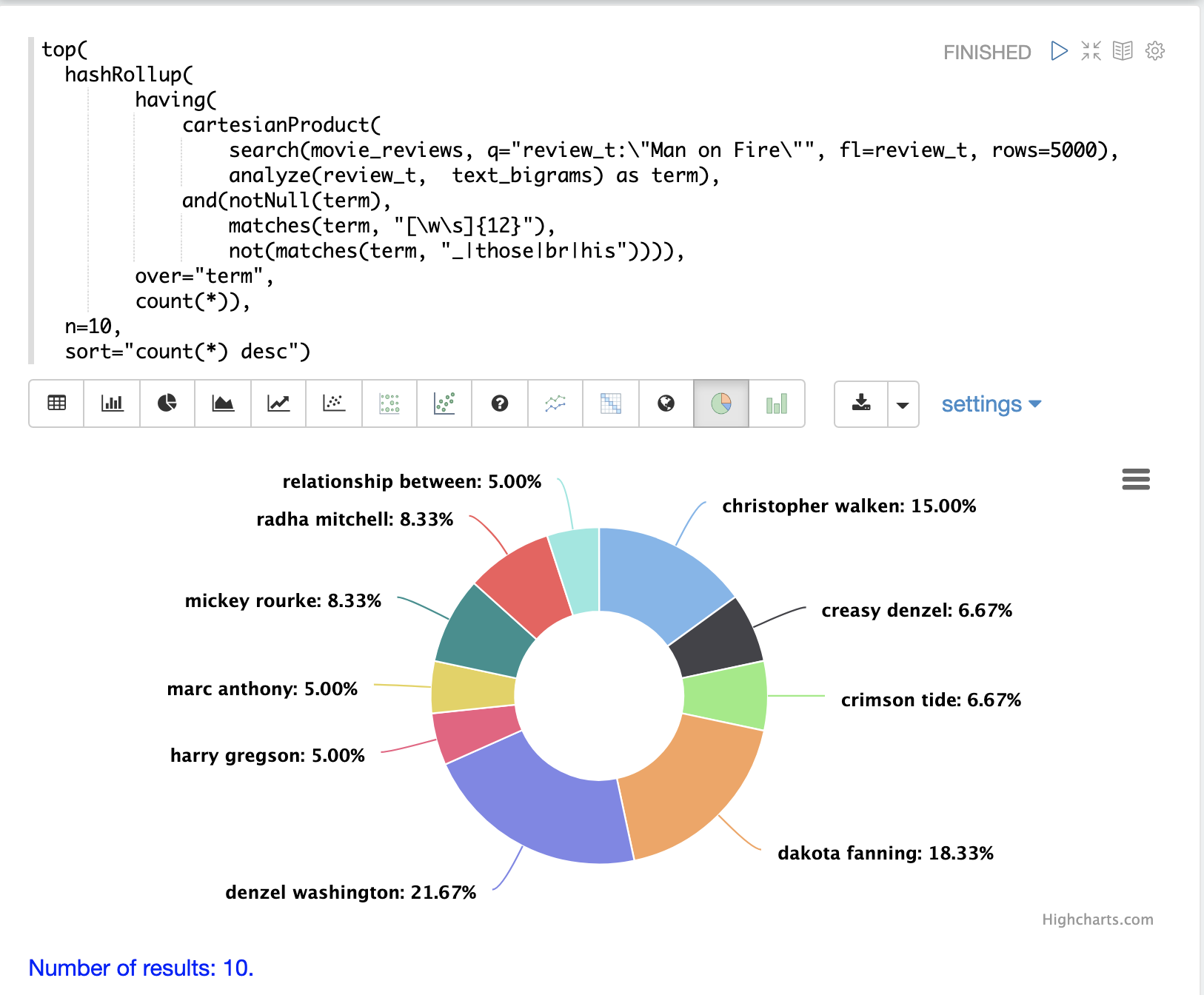
分析器可以以多种不同的方式进行配置,以支持对 NLP 实体(人员、地点、公司等)以及使用正则表达式或词典提取的标记进行聚合。
TF-IDF 词向量
termVectors 函数可用于从 analyze 函数生成的术语构建 TF-IDF 词向量。
termVectors 函数操作一个包含名为 id 的字段和名为 terms 的字段的元组列表。请注意,这与上面文档注释示例的输出结构完全相同。
termVectors 函数从元组列表构建一个矩阵。矩阵中每一行对应列表中的一个元组。矩阵中每一列对应 terms 字段中的一个术语。
let(echo="c, d", (1)
a=select(search(collection3, q="*:*", fl="id, subject", sort="id asc"), (2)
id,
analyze(subject, subject_bigram) as terms),
b=termVectors(a, minTermLength=4, minDocFreq=0, maxDocFreq=1), (3)
c=getRowLabels(b), (4)
d=getColumnLabels(b))下面的示例基于文档注释示例构建。
| 1 | echo 参数将回显变量 c 和 d,因此输出将包括行和列标签,这些标签将在表达式中稍后定义。 |
| 2 | 元组列表存储在变量 a 中。termVectors 函数操作变量 a,并构建一个包含 2 行和 4 列的矩阵。 |
| 3 | termVectors 函数将词向量矩阵的行和列标签设置为变量 b。行标签是文档 ID,列标签是术语。 |
| 4 | getRowLabels 和 getColumnLabels 函数返回行和列标签,然后将其存储在变量 c 和 d 中。 |
当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"c": [
"1",
"2"
],
"d": [
"analysis example",
"example number",
"number two",
"text analysis"
]
},
{
"EOF": true,
"RESPONSE_TIME": 5
}
]
}
}TF-IDF 值
词向量矩阵中的值是每个文档中每个术语的 TF-IDF 值。下面的示例显示了矩阵的值。
let(a=select(search(collection3, q="*:*", fl="id, subject", sort="id asc"),
id,
analyze(subject, subject_bigram) as terms),
b=termVectors(a, minTermLength=4, minDocFreq=0, maxDocFreq=1))当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"b": [
[
1.4054651081081644,
0,
0,
1.4054651081081644
],
[
0,
1.4054651081081644,
1.4054651081081644,
0
]
]
},
{
"EOF": true,
"RESPONSE_TIME": 5
}
]
}
}限制噪声
使用词向量时,一个关键的挑战是文本通常具有大量的噪声,这些噪声会掩盖数据中的重要术语。termVectors 函数有几个参数旨在过滤掉不太有意义的术语。这也很重要,因为消除噪声术语有助于使词向量矩阵足够小,以便可以舒适地放入内存中。
有四个参数旨在从词向量矩阵中过滤噪声术语
minTermLength-
可选
默认值:
3将术语包含在矩阵中所需的最小术语长度。
minDocFreq-
可选
默认值:
.05该术语必须出现在索引中才能被包括在内的最小文档百分比,表示为
0和1之间的数字。 maxDocFreq-
可选
默认值:
.5该术语可以出现在索引中才能被包括在内的最大文档百分比,表示为
0和1之间的数字。 exclude-
可选
默认值: 无
一个以逗号分隔的字符串列表,用于排除术语。如果术语包含任何排除的字符串,则该术语将从词向量中排除。