SQL 查询语言
Solr SQL 模块通过将 SQL 与 Solr 的全文搜索功能无缝结合,将 SQL 查询的强大功能带到 Solr。支持 MapReduce 样式和 JSON 分面 API 聚合,这意味着 SQL 查询可用于支持高查询量和高基数用例。
模块
这通过 sql Solr 模块提供,该模块在使用前需要启用。
SQL 架构
SQL 接口允许将 SQL 查询发送到 Solr,并获取流式传输的文档作为响应。在底层,Solr 的 SQL 接口使用 Apache Calcite SQL 引擎将 SQL 查询转换为作为流表达式实现的物理查询计划。
有关 Solr 如何支持 Solr 的 SQL 查询的更多信息,请参阅下面的配置部分。
Solr 集合和数据库表
在标准 SELECT 语句(如 SELECT <表达式> FROM <表>)中,表名对应于 Solr 集合名称。表名不区分大小写。
SQL 查询中的列名直接映射到正在查询的集合的 Solr 索引中的字段。这些标识符区分大小写。支持别名,并且可以在 ORDER BY 子句中引用。
SELECT * 语法(用于指示所有字段)仅支持带有 LIMIT 子句的查询。score 字段只能用于包含 LIMIT 子句的查询。
例如,我们可以索引 Solr 的示例文档,然后构造如下的 SQL 查询
SELECT name_exact as name, manu as mfr, price as retail FROM techproducts ORDER BY retail DESC我们在 Solr 中使用的集合是 "techproducts",我们要求返回 "name_exact"、"manu" 和 "price" 字段,并按别名 "retail" 进行排序,以显示从最贵到最便宜的产品。
Solr SQL 语法
Solr 支持广泛的 SQL 语法。
|
SQL 解析器不区分大小写
Solr 用来转换 SQL 语句的 SQL 解析器不区分大小写。但是,为了便于阅读,此页面上的所有示例都使用大写关键字。 |
|
仅在使用 LIMIT 时才支持 SELECT *
通常,您应该显式投影每个查询需要返回的字段,并避免使用 |
SELECT 语句
Solr 支持有限和无限的 select 查询。两种查询类型的语法相同,只是 SQL 语句中存在 LIMIT 子句。但是,它们的执行计划和对数据存储方式的要求非常不同。下面的部分探讨了这两种类型的查询。
WHERE 子句和布尔谓词
|
WHERE 子句的谓词一侧必须有一个字段。不支持两个常量 |
WHERE 子句允许将 Solr 的搜索语法注入到 SQL 查询中。例如:
WHERE fieldC = 'term1 term2'上面的谓词将对 fieldC 中的短语 'term1 term2' 执行全文搜索。
要执行非短语查询,只需在单引号内添加括号。例如:
WHERE fieldC = '(term1 term2)'上面的谓词将在 fieldC 中搜索 term1 OR term2。
Solr 范围查询语法可以按如下方式使用:
WHERE fieldC = '[0 TO 100]'可以按如下方式指定复杂的布尔查询:
WHERE ((fieldC = 'term1' AND fieldA = 'term2') OR (fieldB = 'term3'))要指定 NOT 查询,可以使用 AND NOT 语法,如下所示:
WHERE (fieldA = 'term1') AND NOT (fieldB = 'term2')支持的 WHERE 运算符
SQL 查询接口支持并向下推送大多数常见的 SQL 运算符,特别是:
| 运算符 | 描述 | 示例 | Solr 查询 |
|---|---|---|---|
= |
等于 |
|
|
<> |
不等于 |
|
|
> |
大于 |
|
|
>= |
大于或等于 |
|
|
< |
小于 |
|
|
<= |
小于或等于 |
|
|
IN |
指定多个值(多个 OR 子句的简写) |
|
|
LIKE |
在字符串或文本字段上使用通配符匹配 |
|
|
BETWEEN |
范围匹配 |
|
|
IS NULL |
匹配具有空值的列 |
|
(*:* -field:*) |
IS NOT NULL |
匹配具有值的列 |
|
|
-
使用
<>代替!=表示不等于 -
IN、LIKE、BETWEEN 支持 NOT 关键字来查找条件不为真的行,例如
fielda NOT LIKE 'day%' -
字符串字面量必须用单引号括起来;双引号表示数据库对象,而不是字符串字面量。
-
可以使用星号通配符进行简单的 LIKE 匹配,例如
field = 'sam*';这是 Solr 特有的,而不是 SQL 标准的一部分。 -
IN子句的最大值数量受为您的集合配置的maxBooleanClauses限制。 -
当在多值字段上执行 ANDed 范围查询时,如果 ANDed 谓词看起来是不相交的集合,则 Apache Calcite 会短路为零结果。例如,b_is <= 2 AND b_is >= 5 从单值字段的角度来看,对 Calcite 来说似乎是不相交的集合。但是,对于多值字段,情况可能并非如此,因为 Solr 可能会匹配文档。解决方法是直接在用括号括起来的等于表达式中使用 Solr 查询语法:b_is = '(+[5 TO *] +[* TO 2])'
ORDER BY 子句
ORDER BY 子句直接映射到 Solr 字段。支持多个 ORDER BY 字段和方向。
在指定了限制的查询中,score 字段在 ORDER BY 子句中被接受。
如果 ORDER BY 子句包含 GROUP BY 子句中的确切字段,则返回的结果没有限制。如果 ORDER BY 子句包含与 GROUP BY 子句不同的字段,则会自动应用 100 的限制。要增加此限制,您必须在 LIMIT 子句中指定一个值。
Order by 字段区分大小写。
使用 FETCH 的 OFFSET
指定 ORDER BY 子句的查询也可以使用 OFFSET(从 0 开始的索引)和 FETCH 运算符来分页浏览结果;不支持没有 FETCH 的 OFFSET,并且会生成异常。例如,以下查询请求第二页 10 个结果:
ORDER BY ... OFFSET 10 FETCH NEXT 10 ROWS ONLY使用 SQL 进行分页与使用 start 和 rows 在 Solr 查询中进行分页存在相同的性能损失,在分布式查询中必须从每个分片过度获取 OFFSET + LIMIT 文档,然后对来自每个分片的结果进行排序,以生成返回给客户端的结果页。因此,此功能应仅用于较小的 OFFSET / FETCH 大小,例如每个分片最多分页 10,000 个文档。Solr SQL 不会强制执行任何硬性限制,但是您深入结果的程度越深,每个后续的页面请求都会花费更长的时间并消耗更多的资源。SQL 中不支持 Solr 用于深度分页的 cursorMark 功能;请改用没有 LIMIT 的 SQL 查询通过 /export 处理程序流式传输大型结果集。SQL OFFSET 不适用于深度分页类型的用例。
LIMIT 子句
将结果集限制为指定的大小。在上面的示例中,子句 LIMIT 100 将结果集限制为 100 条记录。
有限制和无限限制的查询之间有一些区别需要注意:
-
有限制查询支持字段列表和
ORDER BY中的score。无限查询不支持。 -
有限制查询允许字段列表中的任何存储字段。无限查询要求字段存储为 DocValues 字段。
-
有限制查询允许
ORDER BY列表中的任何索引字段。无限查询要求字段存储为 DocValues 字段。 -
如果一个字段被索引但未存储或没有 docValues,则可以在该字段上进行过滤,但不能在结果中返回它。
SELECT DISTINCT 查询
SQL 接口支持 SELECT DISTINCT 查询的 MapReduce 和 Facet 实现。
MapReduce 实现将元组混洗到执行 Distinct 操作的工作节点。此实现可以在极高基数字段上执行 Distinct 操作。
Facet 实现使用 JSON Facet API 将 Distinct 操作下推到搜索引擎中。此实现专为低到中等基数字段上的高性能、高 QPS 场景而设计。
JDBC 驱动程序和 HTTP 接口中都有 aggregationMode 参数,用于选择底层实现(map_reduce 或 facet)。两种实现的 SQL 语法是相同的。
SELECT distinct fieldA as fa, fieldB as fb FROM tableA ORDER BY fa desc, fb desc统计函数
SQL 接口支持对数值字段计算的简单统计信息。支持的函数包括 COUNT(*)、COUNT(DISTINCT field)、APPROX_COUNT_DISTINCT(field)、MIN、MAX、SUM 和 AVG。
由于这些函数从不需要对数据进行混洗,因此会将聚合下推到搜索引擎中,并由 Stats Component 生成。
SELECT COUNT(*) as count, SUM(fieldB) as sum FROM tableA WHERE fieldC = 'Hello'APPROX_COUNT_DISTINCT 指标使用 Solr 的 HyperLogLog (hll) 统计函数来计算给定字段的近似基数,当查询性能很重要且不需要精确计数时应使用此指标。
GROUP BY 聚合
SQL 接口还支持 GROUP BY 聚合查询。
与 SELECT DISTINCT 查询一样,SQL 接口支持 MapReduce 实现和 Facet 实现。MapReduce 实现可以在极高基数字段上构建聚合。Facet 实现提供对具有中等基数字段的高性能聚合。
HAVING 子句
HAVING 子句可以包含字段列表中列出的任何函数。支持如下复杂的 HAVING 子句:
SELECT fieldA, fieldB, COUNT(*), SUM(fieldC), AVG(fieldY)
FROM tableA
WHERE fieldC = 'term1 term2'
GROUP BY fieldA, fieldB
HAVING ((SUM(fieldC) > 1000) AND (AVG(fieldY) <= 10))
ORDER BY SUM(fieldC) ASC
LIMIT 100聚合模式
Solr 的 SQL 功能可以通过两种方式处理聚合(结果分组):
-
facet:这是 默认 的聚合模式,它使用 JSON Facet API 或 StatsComponent 进行聚合。在这种情况下,聚合逻辑被下推到搜索引擎中,只有聚合通过网络发送。这是 Solr 的正常运行模式。当 GROUP BY 字段的基数较低到中等时,速度很快。但是当 GROUP BY 字段中存在高基数字段时,它会崩溃。 -
map_reduce:此实现将元组混洗到工作节点,并在工作节点上执行聚合。它涉及对整个结果集进行排序和分区,然后将其发送到工作节点。在这种方法中,元组到达工作节点时会按 GROUP BY 字段排序。然后,工作节点可以一次汇总一个组的聚合。这允许无限基数聚合,但您需要付出将整个结果集通过网络发送到工作节点的代价。
这些模式在向 Solr 发送请求时,通过 aggregationMode 属性进行定义。
聚合模式的选择取决于您所使用的字段的基数。如果您分组的字段的基数较低到中等,则 “facet” 聚合模式将提供更高的性能,因为它只返回最终的分组,非常类似于现在 facet 的工作方式。但是,如果您的字段具有高基数,则使用工作节点的 “map_reduce” 聚合模式会提供更高的性能。
配置
用于 SQL 界面的请求处理程序被配置为隐式加载,这意味着启动使用此功能几乎无需任何操作。
/sql 请求处理程序
/sql 处理程序是并行 SQL 界面的前端。所有 SQL 查询都将发送到 /sql 处理程序进行处理。当在 map_reduce 模式下运行 GROUP BY 和 SELECT DISTINCT 查询时,该处理程序还会协调分布式 MapReduce 作业。默认情况下,/sql 处理程序将从其自己的集合中选择工作节点来处理分布式操作。在这种默认情况下,/sql 处理程序所在的集合充当 MapReduce 查询的默认工作集合。
默认情况下,/sql 请求处理程序配置为隐式处理程序,这意味着它始终在每个 Solr 安装中启用,无需进一步配置。
SQL 请求的授权
如果您的 Solr 集群配置为使用 基于规则的授权插件,那么您需要在您打算执行 SQL 查询的所有集合的 /sql、/select 和 /export 端点上授予 GET 和 POST 权限。/select 端点用于 LIMIT 查询,而 /export 处理程序用于没有 LIMIT 的查询,因此在大多数情况下,您需要授予对两者的访问权限。如果您使用工作集合用于 /sql 处理程序,那么您只需要授予对工作集合的 /sql 端点的访问权限,而无需授予数据层中的集合的访问权限。在后台,SQL 处理程序还会使用内部 Solr 服务器标识向 /admin/luke 端点发送请求,以获取集合的模式元数据。因此,您无需为用户授予执行 SQL 查询的 /admin/luke 端点的显式权限。
|
如下面的 最佳实践 部分所述,您可能需要为并行 SQL 查询设置单独的集合。如果您有高基数字段和大量数据,请务必查看该部分并考虑使用单独的集合。 |
/stream 和 /export 请求处理程序
流式 API 是 SolrCloud 的可扩展并行计算框架。流式表达式为流式 API 提供了查询语言和序列化格式。
流式 API 提供对快速 MapReduce 的支持,允许它在极大的数据集上执行并行关系代数。在底层,SQL 界面使用 Apache Calcite SQL 解析器解析 SQL 查询。然后,它将查询转换为并行查询计划。并行查询计划使用流式 API 和流式表达式表示。
与 /sql 请求处理程序一样,/stream 和 /export 请求处理程序也配置为隐式处理程序,无需进一步配置。
字段
在某些情况下,SQL 查询中使用的字段必须配置为 DocValue 字段。如果查询是无限制的,则所有字段都必须是 DocValue 字段。如果查询是有限制的(使用 limit 子句),则字段不必启用 DocValues。
|
多值字段
项目列表中的多值字段将作为值 |
JDBC 驱动程序
JDBC 驱动程序随 SolrJ 一起提供。以下是使用 JDBC 驱动程序创建连接和执行查询的示例代码
Connection con = null;
try {
con = DriverManager.getConnection("jdbc:solr://" + zkHost + "?collection=collection1&aggregationMode=map_reduce&numWorkers=2");
stmt = con.createStatement();
rs = stmt.executeQuery("SELECT a_s, sum(a_f) as sum FROM collection1 GROUP BY a_s ORDER BY sum desc");
while(rs.next()) {
String a_s = rs.getString("a_s");
double s = rs.getDouble("sum");
}
} finally {
rs.close();
stmt.close();
con.close();
}连接 URL 必须包含 zkHost 和 collection 参数。该集合必须是指定 ZooKeeper 主机上的有效 SolrCloud 集合。该集合还必须配置有 /sql 处理程序。aggregationMode 和 numWorkers 参数是可选的。
HTTP 界面
Solr 通过 /sql 处理程序接受 SQL 查询。
以下是在 facet 模式下执行 SQL 聚合查询的示例 curl 命令
curl --data-urlencode 'stmt=SELECT to, count(*) FROM collection4 GROUP BY to ORDER BY count(*) desc LIMIT 10' http://localhost:8983/solr/collection4/sql?aggregationMode=facet以下是示例结果集
{"result-set":{"docs":[
{"count(*)":9158,"to":"pete.davis@enron.com"},
{"count(*)":6244,"to":"tana.jones@enron.com"},
{"count(*)":5874,"to":"jeff.dasovich@enron.com"},
{"count(*)":5867,"to":"sara.shackleton@enron.com"},
{"count(*)":5595,"to":"steven.kean@enron.com"},
{"count(*)":4904,"to":"vkaminski@aol.com"},
{"count(*)":4622,"to":"mark.taylor@enron.com"},
{"count(*)":3819,"to":"kay.mann@enron.com"},
{"count(*)":3678,"to":"richard.shapiro@enron.com"},
{"count(*)":3653,"to":"kate.symes@enron.com"},
{"EOF":"true","RESPONSE_TIME":10}]}
}请注意,结果集是由键/值对与 SQL 列列表匹配的元组组成的数组。最后一个元组包含 EOF 标志,该标志表示流的结束。
并行 SQL 查询
前面的部分介绍了 SQL 界面如何将 SQL 语句转换为流式表达式。请求的参数之一是 aggregationMode,它定义查询是应使用类似 MapReduce 的混洗技术,还是应将操作下推到搜索引擎中。
并行查询
并行 SQL 架构由三个逻辑层组成:SQL 层、工作层和数据表层。默认情况下,SQL 层和工作层会合并到同一个物理 SolrCloud 集合中。
SQL 层
SQL 层是 /sql 处理程序所在的层。/sql 处理程序接收 SQL 查询并将其转换为并行查询计划。然后,它选择工作节点来执行该计划,并将查询计划发送到每个工作节点以并行运行。
工作节点执行完查询计划后,/sql 处理程序会对工作节点返回的元组执行最终合并。
工作层
工作层中的工作节点从 /sql 处理程序接收查询计划并执行并行查询计划。并行执行计划包括需要在数据表层上进行的查询以及满足查询所需的关系代数。分配给查询的每个工作节点都会对来自数据表的 1/N 元组进行混洗。工作节点执行查询计划并将元组流回工作节点。
数据表层
数据表层是表所在的层。每个表都是其自身的 SolrCloud 集合。数据表层从工作节点接收查询并发出元组(搜索结果)。数据表层还处理发送给工作节点的元组的初始排序和分区。这意味着元组在到达网络之前始终会进行排序和分区。分区后的元组将以正确的排序顺序直接发送到正确的工作节点,以便进行归约。
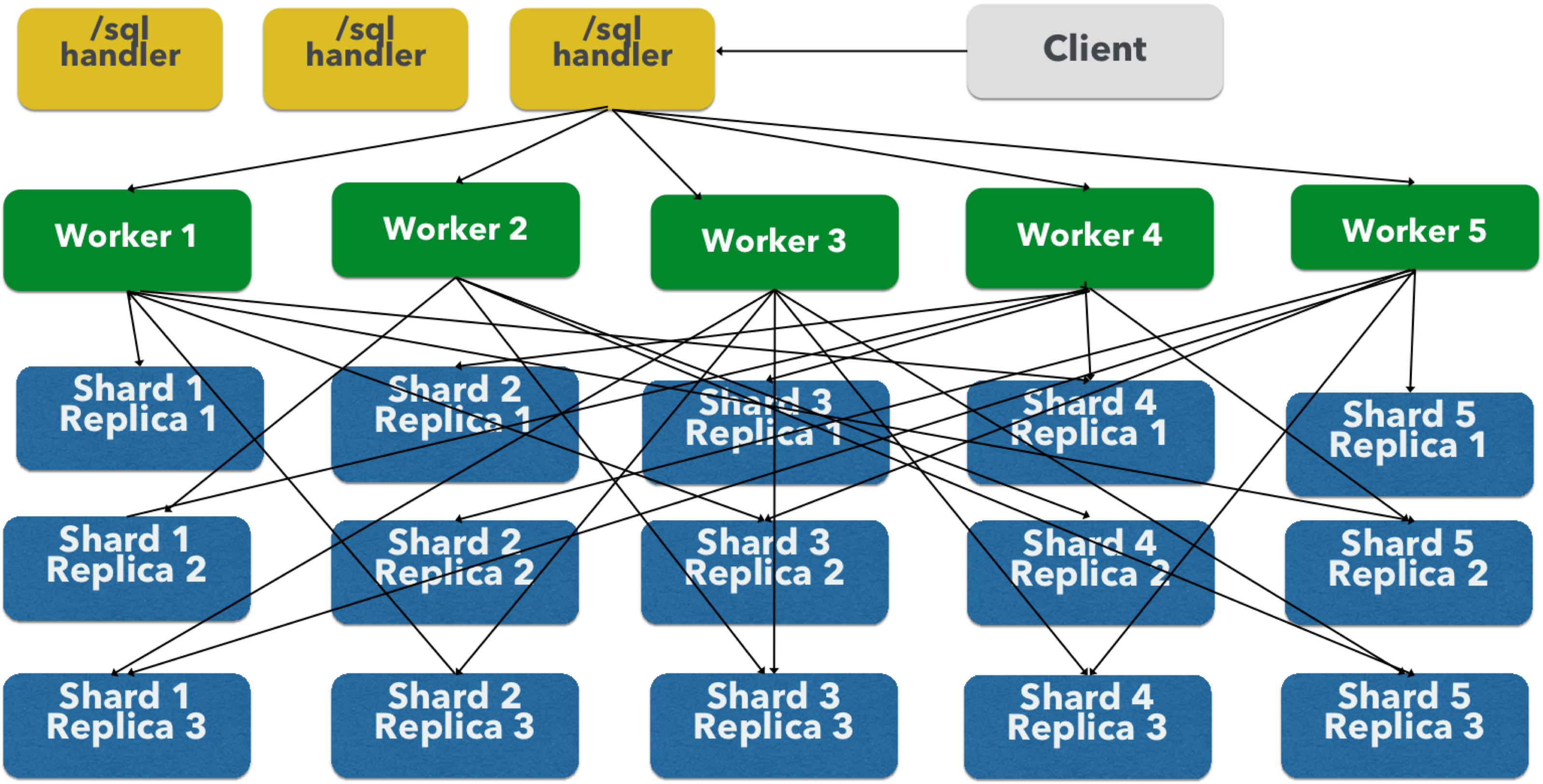
上图显示了为了清晰起见而分解为不同 SolrCloud 集合的三个层。实际上,默认情况下,/sql 处理程序和工作集合共享同一个集合。
该图显示了单个并行 SQL 查询(基于 MapReduce 的 SQL)的网络流。当为 GROUP BY 聚合或 SELECT DISTINCT 查询使用 map_reduce 聚合模式时,将使用此网络流。当使用 facet 聚合模式时,将使用传统的 SolrCloud 网络流(没有工作节点)。 |
以下是对流程的描述
-
客户端向
/sql处理程序发送 SQL 查询。该请求由单个/sql处理程序实例处理。 -
/sql处理程序解析 SQL 查询并创建并行查询计划。 -
查询计划将发送到工作节点(绿色)。
-
工作节点并行执行该计划。该图显示了每个工作节点都与数据表层(蓝色)中的集合进行通信。
-
数据表层中的集合是 SQL 查询中的表。请注意,该集合有五个分片,每个分片有 3 个副本。
-
请注意,每个工作节点都与每个分片的一个副本进行通信。由于有 5 个工作节点,因此每个工作节点都会从每个分片返回 1/5 的搜索结果。分区是在数据表层内部完成的,因此网络上没有数据重复。
-
另请注意,通过此设计,数据层中的所有副本都同时混洗(排序和分区)数据。随着分片、副本和工作节点的数量增加,此设计允许将大量的计算能力应用于单个查询。
-
工作节点并行处理从数据表层返回的元组。工作节点执行满足查询计划所需的关系代数。
-
工作节点将元组流回
/sql处理程序,在其中完成最终合并,最后将元组流回客户端。
SQL 客户端和数据库可视化工具
SQL 界面支持从 SQL 客户端和数据库可视化工具发送的查询。
本指南包含配置以下工具和客户端的文档
通用客户端
对于大多数基于 Java 的客户端,需要将以下 jar 文件放在客户端类路径中
-
在
$SOLR_TIP/server/solr-webapp/webapp/WEB-INF/lib/*和$SOLR_TIP/server/lib/ext/*中可以找到 SolrJ 的依赖.jar文件。在 Solr 发行版中,这些依赖与 Solr 自身的依赖没有分开,因此您必须包含所有依赖,或者手动选择所需的精确集合。请参考 maven 发布,以获取您的版本所需的准确依赖项。 -
SolrJ 的
.jar文件位于$SOLR_TIP/server/solr-webapp/webapp/WEB-INF/lib/solr-solrj-<版本>.jar。
如果您使用 Maven,org.apache.solr.solr-solrj 工件包含了所需的 jar 文件。
一旦这些 jar 文件在类路径上可用,Solr JDBC 驱动程序的名称是 org.apache.solr.client.solrj.io.sql.DriverImpl,并且可以使用以下连接字符串格式建立连接
jdbc:solr://SOLR_ZK_CONNECTION_STRING?collection=COLLECTION_NAME连接字符串还可以选择添加其他参数,例如 aggregationMode 和 numWorkers。