索引段和合并
Lucene 索引存储在段中,Solr 提供了几个参数来控制如何写入新段以及何时合并段。
Lucene 索引是“一次写入”文件:一旦将一个段写入永久存储(到磁盘),它就永远不会被更改。这意味着索引实际上由多个文件组成,每个文件都是完整索引的子集。为了防止索引的永久碎片化,会定期合并段。
solrconfig.xml 中的 <indexConfig>
solrconfig.xml 的 <indexConfig> 部分定义了 Lucene 索引写入器的底层行为。
默认情况下,这些设置在 Solr 附带的示例 solrconfig.xml 中被注释掉,这意味着使用默认值。在大多数情况下,默认值都可以。
<indexConfig>
...
</indexConfig>写入新段
以下元素可以在 <indexConfig> 元素下定义,并定义何时将新段写入(“刷新”)到磁盘。
ramBufferSizeMB
一旦累积的文档更新超过了这么多内存空间(以兆字节为单位定义),则挂起的更新将被刷新。这也会创建新段或触发合并。通常,使用此设置比使用 maxBufferedDocs 更可取。如果在 solrconfig.xml 中同时设置了 maxBufferedDocs 和 ramBufferSizeMB,则当达到任一限制时会发生刷新。默认值为 100 MB。
<ramBufferSizeMB>100</ramBufferSizeMB>合并索引段
以下设置定义何时合并段。
mergePolicyFactory
定义如何合并段。
Solr 中的默认设置是使用 TieredMergePolicy,它会合并大小大致相等的段,但受每个层允许的段数的限制。
其他可用的策略是 LogByteSizeMergePolicy 和 LogDocMergePolicy。有关这些策略的更多信息,请参阅 MergePolicy javadocs。
<mergePolicyFactory class="org.apache.solr.index.TieredMergePolicyFactory">
<int name="maxMergeAtOnce">10</int>
<int name="segmentsPerTier">10</int>
<double name="forceMergeDeletesPctAllowed">10.0</double>
<double name="deletesPctAllowed">33.0</double>
</mergePolicyFactory>控制段大小
用户对 TieredMergePolicy(或 LogByteSizeMergePolicy)配置进行的最常见调整是“合并因子”,以更改一次应合并多少段,在 TieredMergePolicy 的情况下,还更改合并段的最大大小。
对于 TieredMergePolicy,这由设置 maxMergeAtOnce(默认值为 10)、segmentsPerTier(默认值为 10)和 maxMergedSegmentMB(默认值为 5000)选项控制。
LogByteSizeMergePolicy 有一个 mergeFactor 选项(默认值为 10)。
要了解为什么这些选项很重要,请考虑在使用 LogByteSizeMergePolicy 时对索引进行更新时会发生什么:文档始终添加到最近打开的段中。当一个段填满时,会创建一个新段,并将后续更新放置在那里。
如果创建新段会导致最低级别的段的数量超过 mergeFactor 值,则所有这些段将合并在一起,形成一个大的段。因此,如果合并因子为 10,则每次合并都会创建一个比其十个组成部分大约大十倍的单个段。当有 10 个这种较大的段时,它们又会被合并成一个更大的单个段。这个过程可以无限期地继续下去。
当使用 TieredMergePolicy 时,过程相同,但不是使用单个 mergeFactor 值,而是使用 segmentsPerTier 设置作为决定是否应该发生合并的阈值,并且 maxMergeAtOnce 设置决定了应该在合并中包含多少个段。
选择最佳的合并因子通常是在索引速度和搜索速度之间进行权衡。索引中段的数量较少通常会加快搜索速度,因为要查找的地方更少。它还可以减少磁盘上的物理文件数量。但是,为了保持段的数量较少,合并会更频繁地发生,这会增加系统的负载并减慢对索引的更新。
相反,保留更多的段可以加快索引速度,因为合并发生的频率较低,因此更新不太可能触发合并。但是,搜索在计算上会变得更加昂贵,并且可能会更慢,因为必须在更多的索引段中查找搜索词。更快的索引更新也意味着更短的提交周转时间,这意味着更及时的搜索结果。
控制已删除文档的百分比
当删除或更新文档时,该文档会被标记为已删除,但在合并段之前不会从索引中删除。在使用默认的 TieredMergePolicy 时,可以调整两个参数,这些参数会影响索引中已删除文档的数量。
forceMergeDeletesPctAllowed-
可选
默认值:
10.0当发出外部
expungeDeletes命令时,任何已删除文档百分比超过此值的段都将被合并到一个新段中,并且与已删除文档相关的数据将被清除。值为0.0将使 expungeDeletes 的行为与optimize本质上相同。 deletesPctAllowed-
可选
默认值:
33.0在正常的段合并期间,会尽最大努力确保索引中已删除文档的总百分比低于此阈值。有效设置介于 20% 和 50% 之间。选择 33% 作为默认值是因为当此设置接近 20% 时,会给系统增加相当大的负载。
自定义合并策略
如果内置合并策略的配置选项不能完全满足您的用例,您可以通过创建在配置中指定的自定义合并策略工厂,或者通过配置一个 合并策略包装器 来对其进行自定义,该包装器使用 wrapped.prefix 配置选项来控制其包装的工厂的配置方式
<mergePolicyFactory class="org.apache.solr.index.SortingMergePolicyFactory">
<str name="sort">timestamp desc</str>
<str name="wrapped.prefix">inner</str>
<str name="inner.class">org.apache.solr.index.TieredMergePolicyFactory</str>
<int name="inner.maxMergeAtOnce">10</int>
<int name="inner.segmentsPerTier">10</int>
</mergePolicyFactory>上面的示例显示了 Solr 的 SortingMergePolicyFactory 被配置为按 "timestamp desc" 对合并段中的文档进行排序,并通过 SortingMergePolicyFactory 的 wrapped.prefix 选项定义的 inner 前缀,包装在一个 TieredMergePolicyFactory 周围,该工厂被配置为使用值 maxMergeAtOnce=10 和 segmentsPerTier=10。有关使用 SortingMergePolicyFactory 的更多信息,请参阅 segmentTerminateEarly 参数。
mergeScheduler
合并调度器控制如何执行合并。默认的 ConcurrentMergeScheduler 使用单独的线程在后台执行合并。另一种选择 SerialMergeScheduler,不使用单独的线程执行合并。
ConcurrentMergeScheduler 具有以下可配置属性。这些属性的默认值是根据底层磁盘驱动器是否为旋转磁盘动态设置的。有关更多详细信息,请参阅 ConcurrentMergeScheduler 的动态默认值。
maxMergeCount-
可选
默认值:无
允许的最大同时合并次数。如果需要合并,但我们已经运行了这么多线程,则索引线程将阻塞,直到合并线程完成。请注意,Solr 一次只会运行最小的
maxThreadCount合并。 maxThreadCount-
可选
默认值:无
应一次运行的最大同时合并线程数。此值必须小于
maxMergeCount。 ioThrottle-
可选
默认值:无
一个布尔值(
true或false)用于显式控制 I/O 节流。默认情况下,启用节流,CMS 将在合并时限制 I/O 吞吐量,以便为其他(搜索、索引)留出一些空间。
<mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler"/><mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler">
<int name="maxMergeCount">9</int>
<int name="maxThreadCount">4</int>
</mergeScheduler>mergedSegmentWarmer
当将 Solr 用于 近实时用例 时,可以配置合并段预热器,以便在合并提交之前预热新合并段上的读取器。对于近实时搜索来说,这不是必需的,但会减少合并完成后打开新的近实时读取器时的搜索延迟。
<mergedSegmentWarmer class="org.apache.lucene.index.SimpleMergedSegmentWarmer"/>复合文件段
每个 Lucene 段通常由十几个左右的文件组成。可以将 Solr 配置为将 Lucene 段的所有文件捆绑到一个使用 .cfs 文件扩展名的单个复合文件中,即“复合文件段”。
由于各种原因,CFS 段在不同的运行时环境中可能会产生轻微的性能损失。例如,文件系统缓冲区通常与打开的文件描述符相关联,这可能会限制每个索引可用的总缓存空间。
在每个进程允许打开的文件数量有限的系统上,CFS 可以避免达到该限制。打开的文件限制也可以使用 Linux/Unix 的 ulimit 命令或类似的其他操作系统命令进行调整。
|
CFS:新段与合并段
要配置新写入的段是否应使用 CFS,请参阅上面描述的 许多 合并策略 实现都支持 |
段信息屏幕
管理 UI 中的“段信息”屏幕可让您查看此核心的底层 Lucene 索引中各种段的可视化效果,其中包含有关每个段的大小(字节和文档数量)以及有关这些段的其他基本元数据的信息。最明显的是已删除文档的数量,但您可以将鼠标悬停在段上以查看其他数字详细信息。
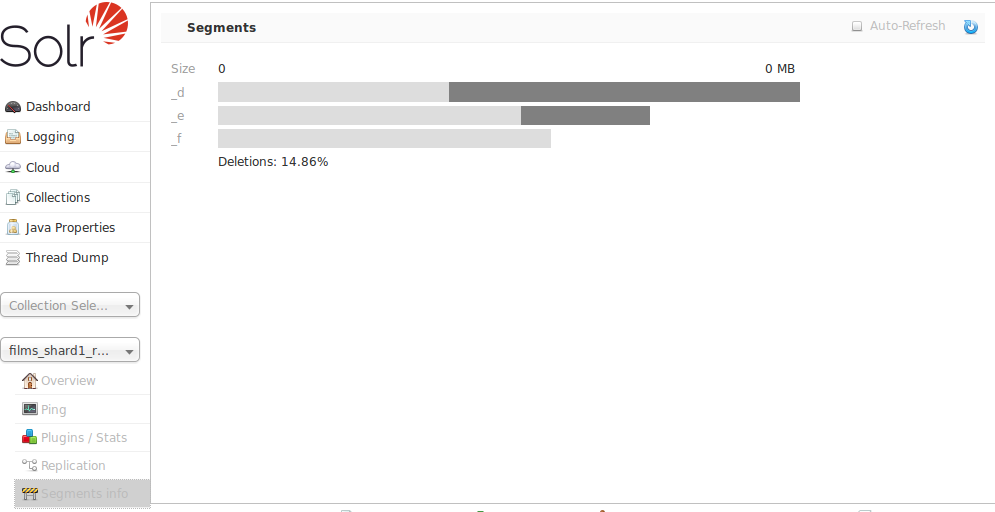
此信息可能对人们有所帮助,从而可以就其数据的最佳 合并设置做出决策。
索引锁
lockType
LockFactory 选项指定要使用的锁定实现。
有效锁定类型选项的集合取决于您配置的 DirectoryFactory。
以下列出的值受 StandardDirectoryFactory(默认值)支持
-
native(默认值)使用NativeFSLockFactory指定本机 OS 文件锁定。如果第二个 Solr 进程尝试访问目录,它将失败。当多个 Solr Web 应用程序尝试共享单个索引时,请勿使用。另请参阅 NativeFSLockFactory javadocs。 -
simple使用SimpleFSLockFactory指定用于锁定的普通文件。另请参阅 SimpleFSLockFactory javadocs。 -
single(专家)使用SingleInstanceLockFactory。用于只读索引目录的特殊情况,或当不可能有多个进程尝试修改索引(即使是按顺序)时。此类型将防止同一 JVM 中的多个核心尝试访问同一索引。如果不同 JVM 中的多个 Solr 实例修改索引,则此类型不会防止索引损坏。 -
hdfs使用HdfsLockFactory支持在 HDFS 文件系统中读取和写入索引和事务日志文件。有关使用此功能的更多详细信息,请参阅 Solr on HDFS 部分。
<lockType>native</lockType>其他索引设置
还有一些其他参数对于您的实现可能很重要。这些设置会影响如何或何时对索引进行更新。
deletionPolicy
控制在回滚的情况下如何保留提交。默认值为 SolrDeletionPolicy,它采用以下参数
maxCommitsToKeep-
可选
默认值:无
要保留的最大提交次数。
maxOptimizedCommitsToKeep-
可选
默认值:无
要保留的最大优化提交次数。
maxCommitAge-
可选
默认值:无
要保留的任何提交的最大年龄。这支持
DateMathParser语法。
<deletionPolicy class="solr.SolrDeletionPolicy">
<str name="maxCommitsToKeep">1</str>
<str name="maxOptimizedCommitsToKeep">0</str>
<str name="maxCommitAge">1DAY</str>
</deletionPolicy>