加载数据
流表达式支持读取、解析、转换、可视化和加载 CSV 和 TSV 格式的数据。这些函数旨在减少数据准备的时间,并允许用户在将数据加载到 Solr 之前开始数据探索。
读取文件
cat 函数可用于读取 $SOLR_HOME 中 userfiles 目录下的文件。此目录必须由用户创建。cat 函数接受两个参数。
第一个参数是以逗号分隔的路径列表。如果路径列表包含目录,cat 将会爬取目录和子目录中的所有文件。如果路径列表仅包含文件,cat 将只读取指定的文件。
第二个参数 maxLines 告诉 cat 总共要读取多少行。如果未提供 maxLines,则 cat 将会读取其爬取的每个文件的所有行。
cat 函数读取爬取的文件中的每一行(最多 maxLines),并为每一行发出一个包含两个字段的元组
-
line: 行中的文本。 -
file: $SOLR_HOME 下的文件的相对路径。
以下是在 iris.csv 文件上使用 maxLines 为 5 的 cat 的示例
cat("iris.csv", maxLines="5")当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"line": "sepal_length,sepal_width,petal_length,petal_width,species",
"file": "iris.csv"
},
{
"line": "5.1,3.5,1.4,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.9,3,1.4,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.7,3.2,1.3,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.6,3.1,1.5,0.2,setosa",
"file": "iris.csv"
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}解析 CSV 和 TSV 文件
parseCSV 和 parseTSV 函数包装了 cat 函数,并解析 CSV(逗号分隔值)和 TSV(制表符分隔值)。这两个函数都期望每个文件的开头有一个 CSV 或 TSV 标头记录。
parseCSV 和 parseTSV 都发出元组,其中标头值映射到每行中它们对应的值。
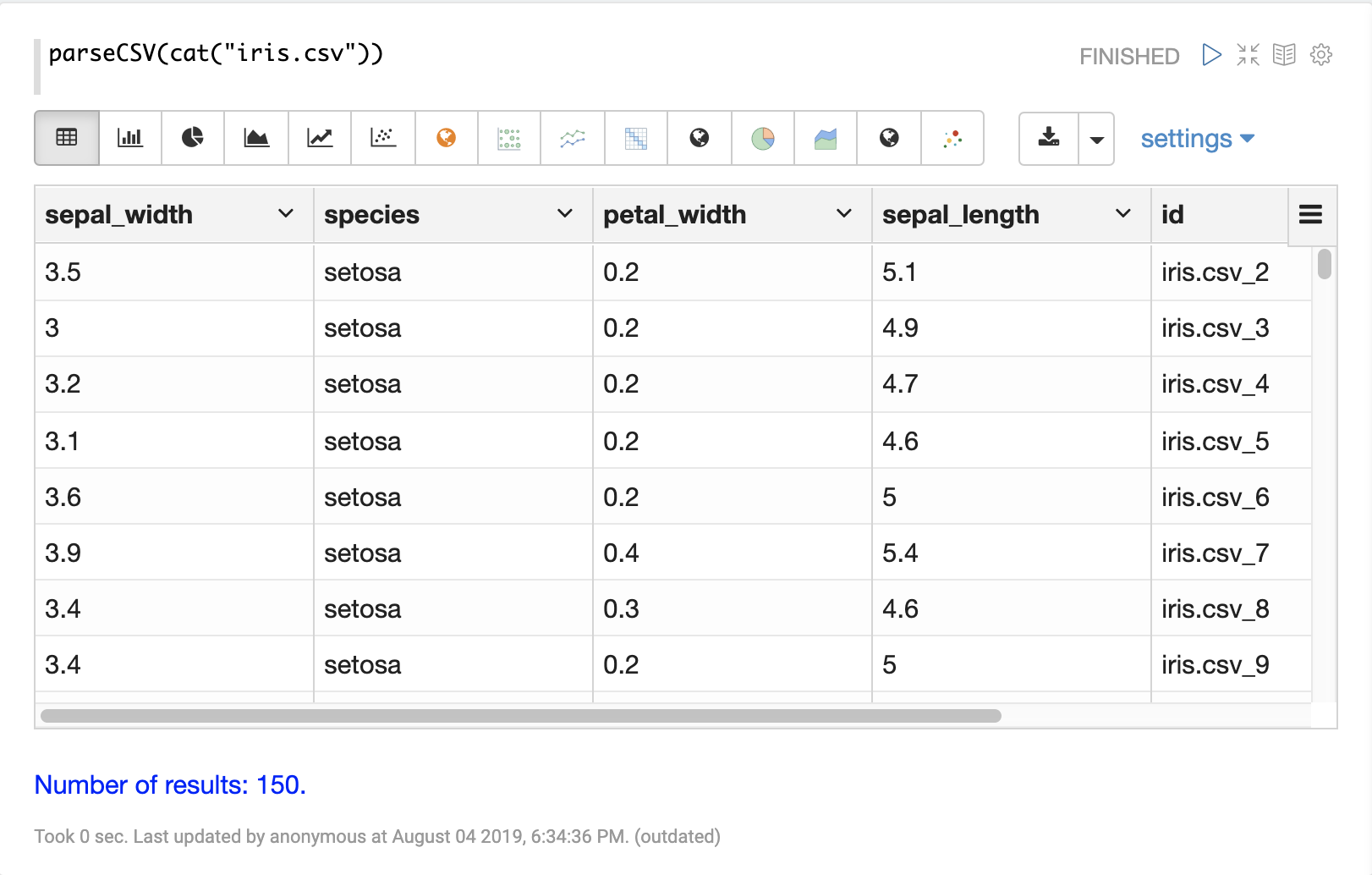
parseCSV(cat("iris.csv", maxLines="5"))当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"sepal_width": "3.5",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "5.1",
"id": "iris.csv_2",
"petal_length": "1.4"
},
{
"sepal_width": "3",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.9",
"id": "iris.csv_3",
"petal_length": "1.4"
},
{
"sepal_width": "3.2",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.7",
"id": "iris.csv_4",
"petal_length": "1.3"
},
{
"sepal_width": "3.1",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.6",
"id": "iris.csv_5",
"petal_length": "1.5"
},
{
"EOF": true,
"RESPONSE_TIME": 1
}
]
}
}可视化
一旦使用 parseCSV 或 parseTSV 将数据解析为元组,就可以使用 Zeppelin-Solr 进行可视化。
下面的示例显示了可视化为表格的 parseCSV 函数的输出。
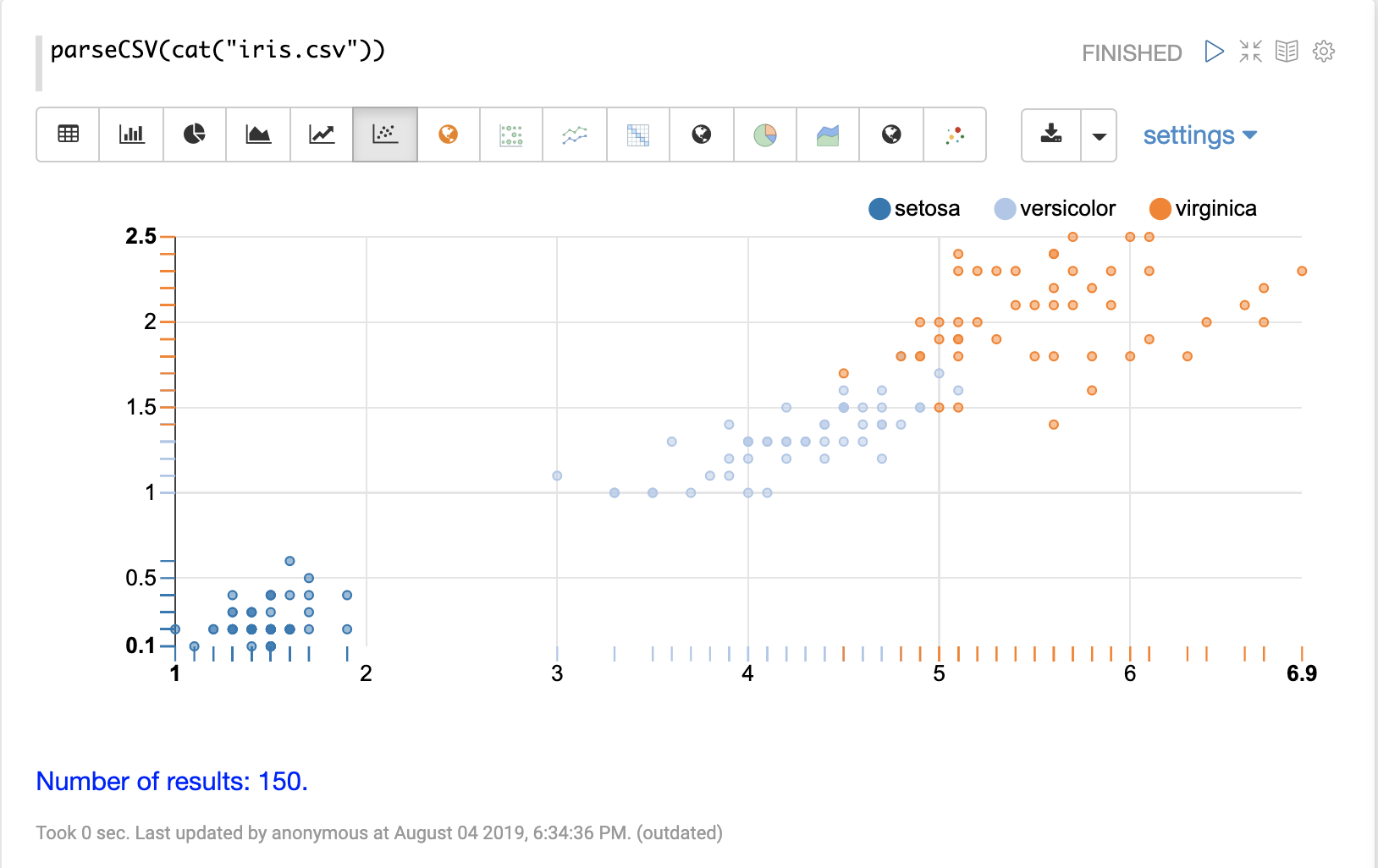
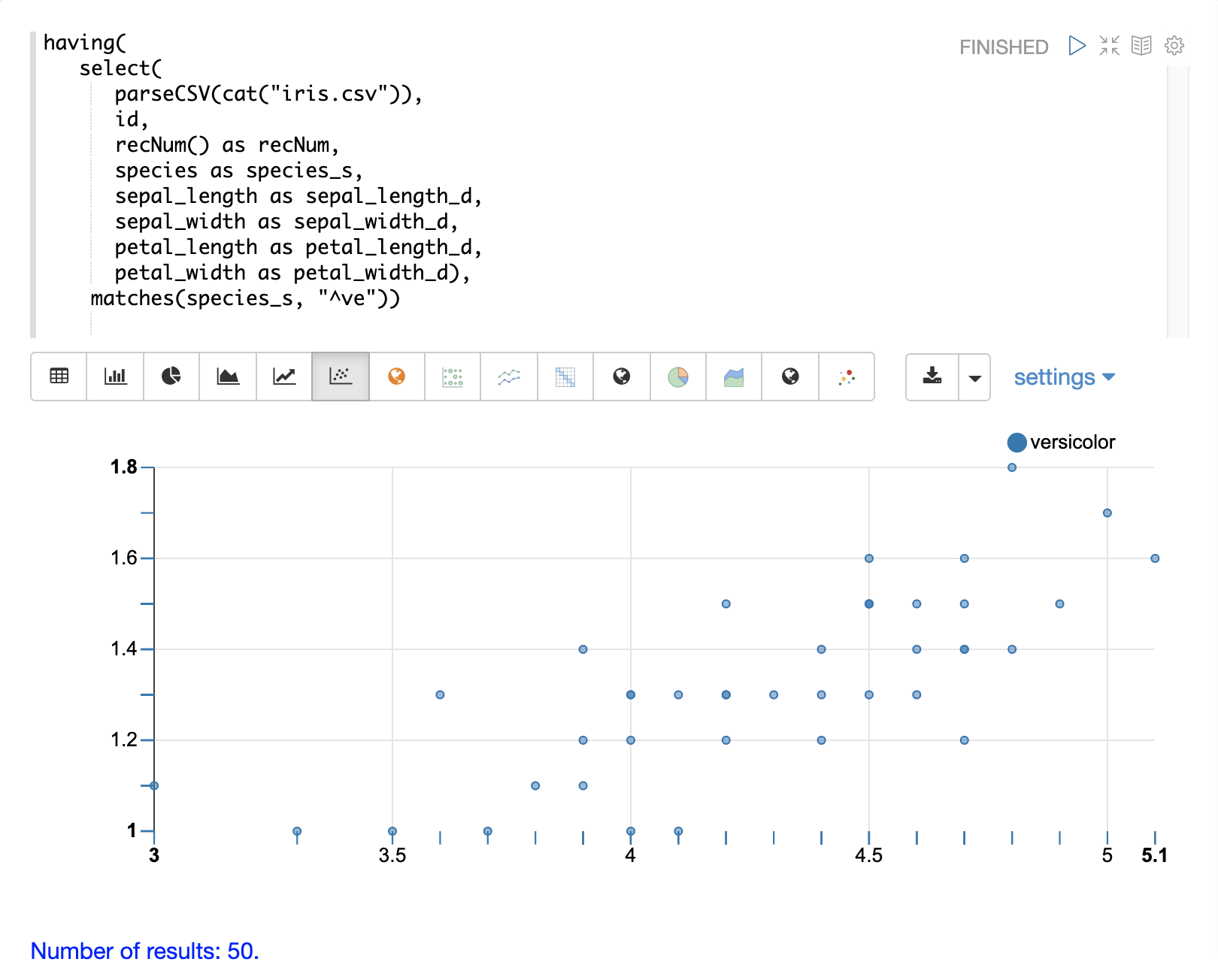
然后,可以使用 Apache Zeppelin 的可视化工具之一来可视化表格中的列。下面的示例显示了按 species 分组的 petal_length 和 petal_width 的散点图。
选择字段和字段类型
可以使用 select 函数从 CSV 文件中选择特定字段,并将它们映射到新的字段名称以进行索引。
CSV 文件中的字段可以使用动态字段后缀映射到字段名称。这种方法允许对模式字段类型进行细粒度控制,而无需对模式文件进行任何更改。
下面是一个选择字段并将它们映射到特定字段类型的示例。

加载数据
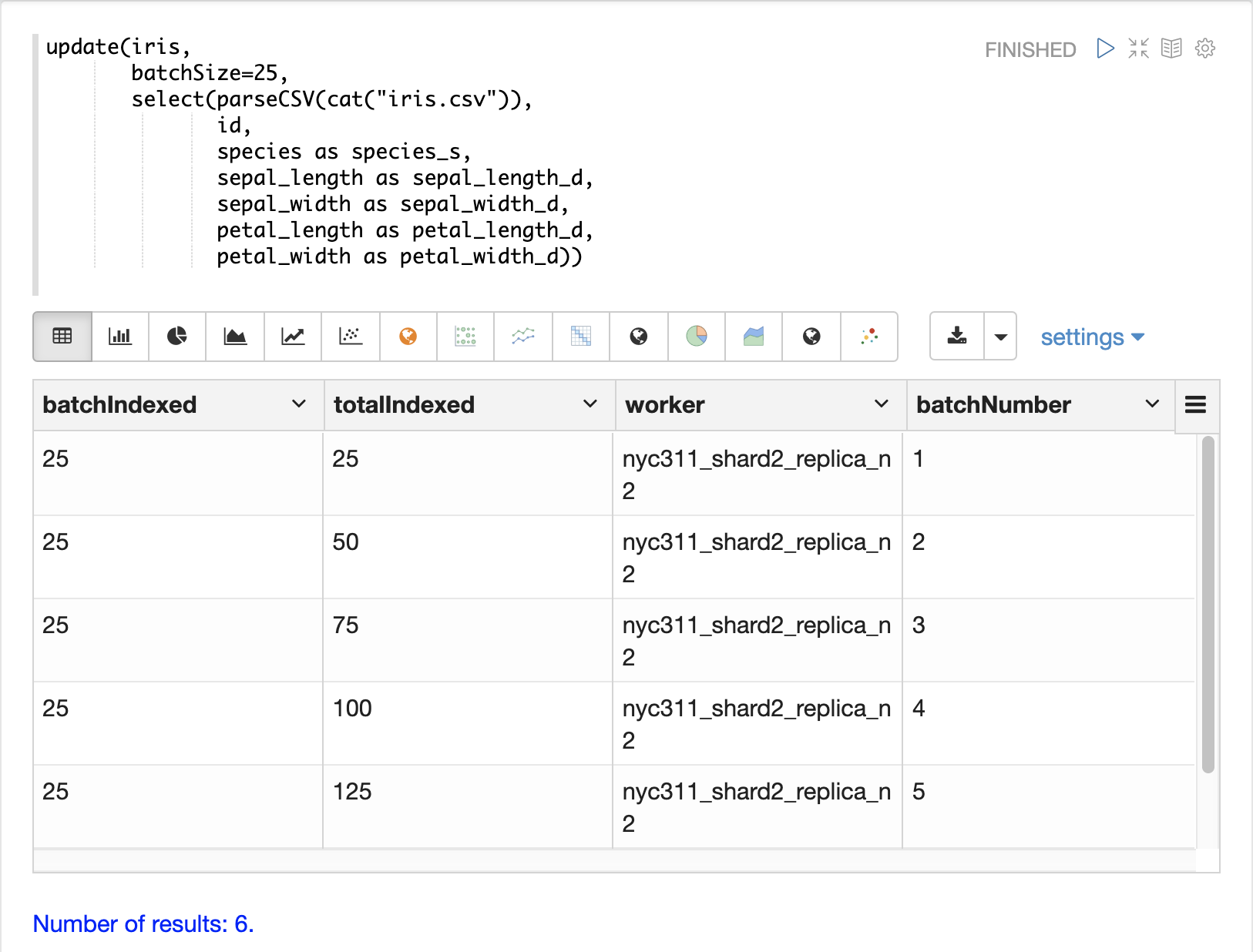
当数据准备好加载时,可以使用 update 函数将数据发送到 SolrCloud 集合进行索引。update 函数将文档分批添加到 Solr,并为每个批次返回一个元组,其中包含关于批次和加载的摘要信息。
在下面的示例中,由于数据集很小,所以使用 Zeppelin-Solr 运行 update 表达式。对于较大的加载,最好从 curl 命令运行加载,其中 update 函数的输出可以假脱机到磁盘。
转换数据
流式表达式和数学表达式提供了一组强大的函数来转换数据。以下部分显示了一些在分析、可视化和加载 CSV 和 TSV 文件时可以应用的有用转换。
唯一 ID
如果数据中还没有 id 字段,parseCSV 和 parseTSV 都会发出一个 id 字段。id 字段是文件路径和行号的串联。如果文件中不存在 id,这是一种确保记录具有一致 id 的便捷方法。
您还可以使用 select 函数将文件中的任何字段映射到 id 字段。concat 函数可用于连接文件中的两个或多个字段以创建 id。或者可以使用 uuid 函数创建随机唯一 id。如果使用 uuid 函数,则必须先删除数据才能重新加载数据,因为 uuid 函数不会在后续加载时为每个文档生成相同的 id。
下面是一个使用 concat 函数创建新 id 的示例。
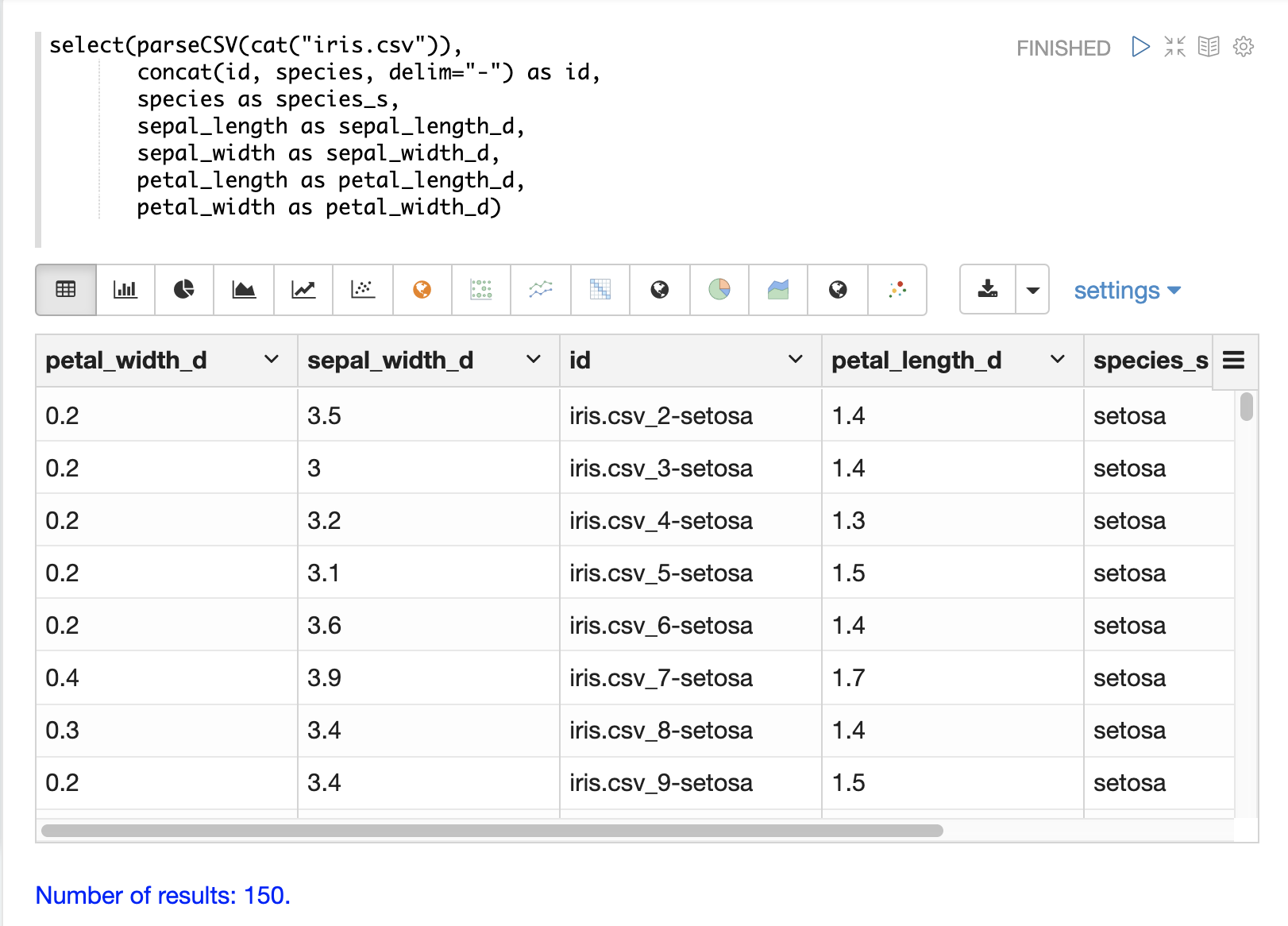
下面是一个使用 uuid 函数创建新 id 的示例。
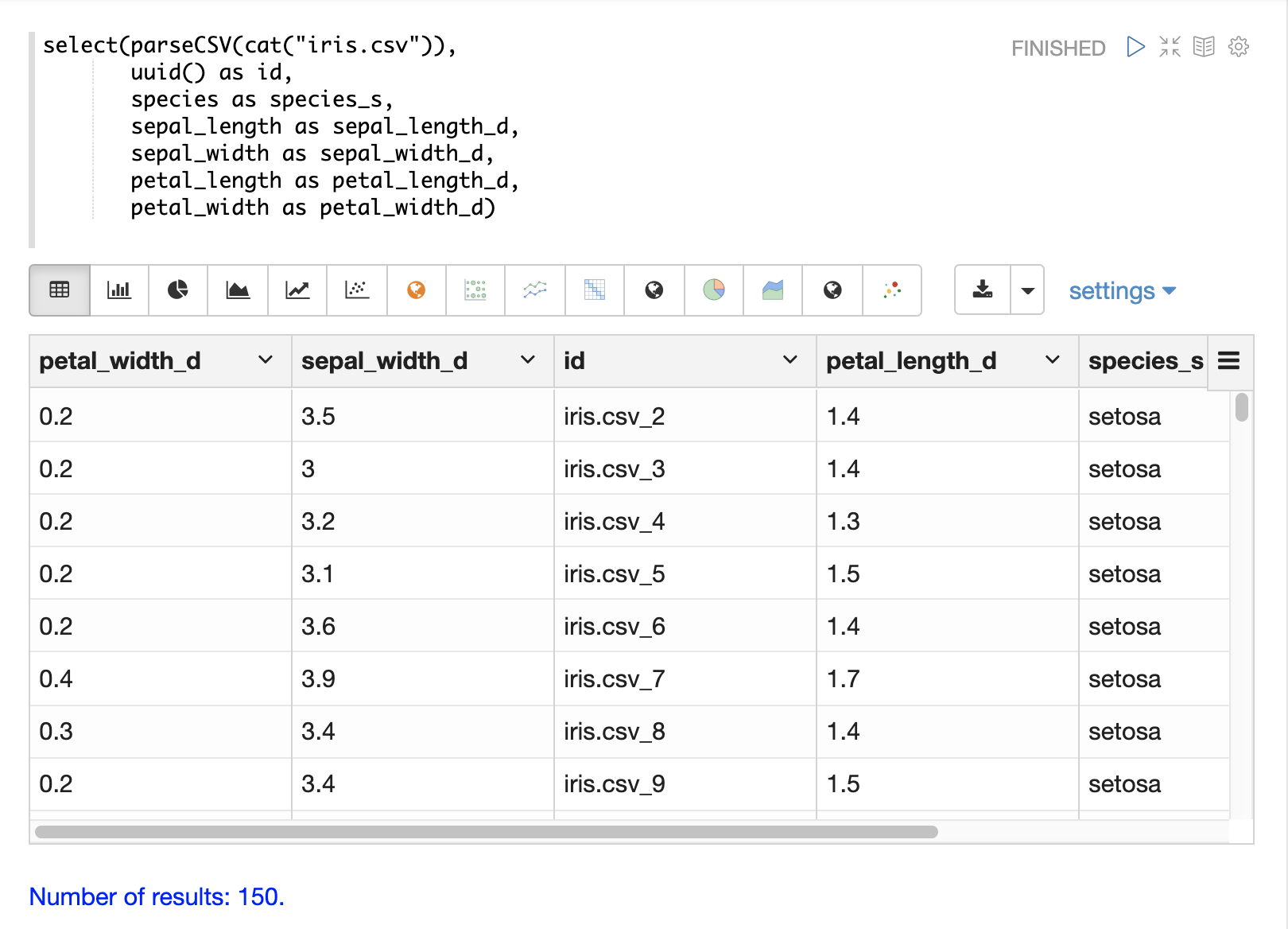
记录号
可以在 select 函数内部使用 recNum 函数为每个元组添加一个记录号。记录号对于跟踪结果集中的位置很有用,并且可以用于过滤策略,例如跳过、分页和跨步,如下面的 过滤结果 部分所述。
下面的示例显示了 recNum 函数的语法
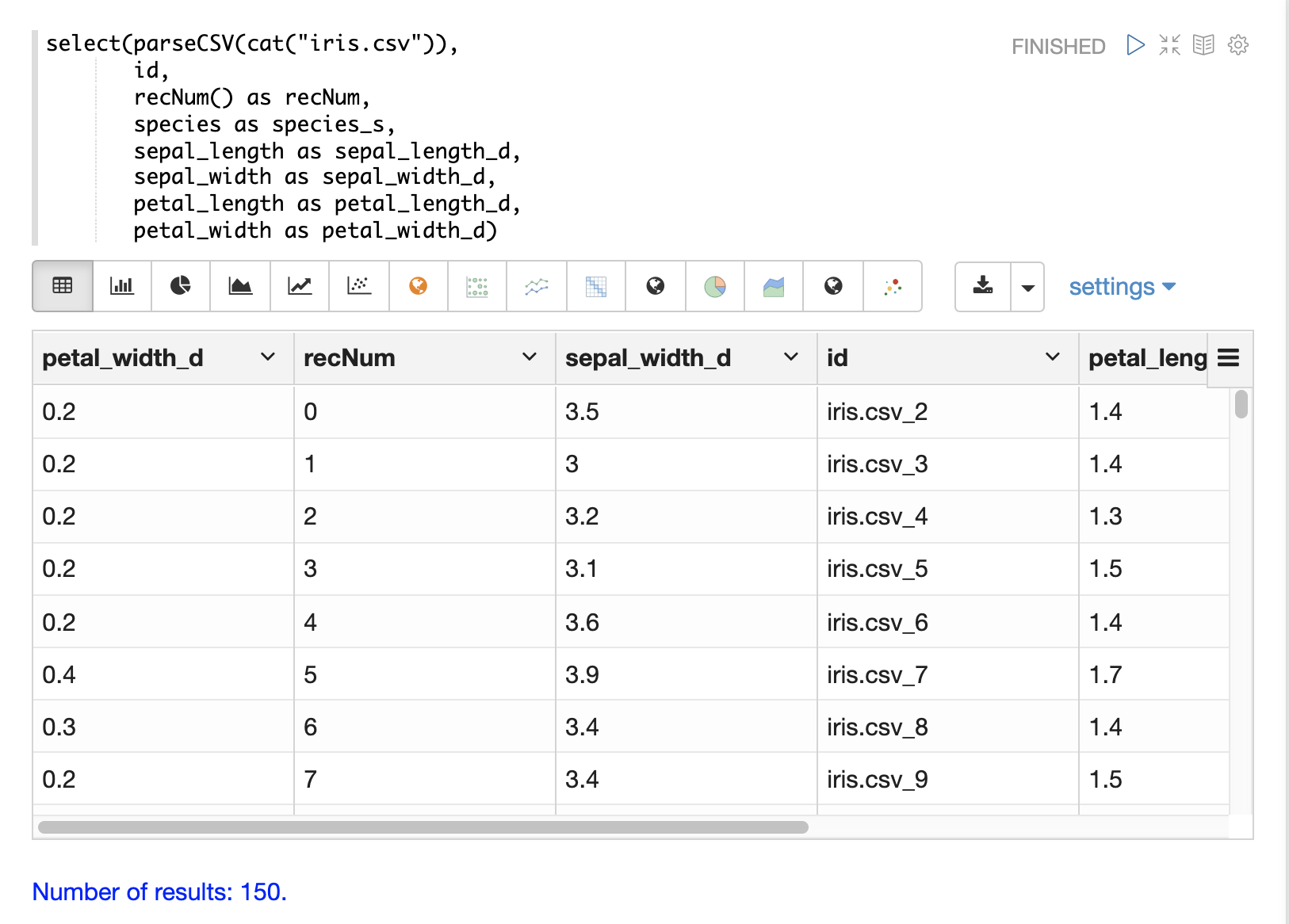
解析日期
可以使用 dateTime 函数将日期解析为加载到 Solr 日期字段所需的 ISO-8601 格式。
我们可以先检查 CSV 文件中数据时间字段的格式
select(parseCSV(cat("yr2017.csv", maxLines="2")),
id,
Created.Date)当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"id": "yr2017.csv_2",
"Created.Date": "01/01/2017 12:00:00 AM"
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}然后我们可以使用 dateTime 函数来格式化日期时间并将其映射到 Solr 日期字段。
dateTime 函数接受三个参数。数据中包含日期字符串的字段、使用 Java SimpleDateFormat 模板解析日期的模板,以及可选的时区。
如果时区不存在,则时区默认为 GMT 时间,除非它包含在日期字符串本身中。
下面是将 dateTime 函数应用于上面示例中的日期格式的示例。
select(parseCSV(cat("yr2017.csv", maxLines="2")),
id,
dateTime(Created.Date, "MM/dd/yyyy hh:mm:ss a", "EST") as cdate_dt)当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"cdate_dt": "2017-01-01T05:00:00Z",
"id": "yr2017.csv_2"
},
{
"EOF": true,
"RESPONSE_TIME": 1
}
]
}
}字符串操作
可以使用 upper、lower、split、valueAt、trim 和 concat 函数来操作 select 函数内部的字符串。
下面的示例显示了用于将 species 字段转换为大写的 upper 函数。
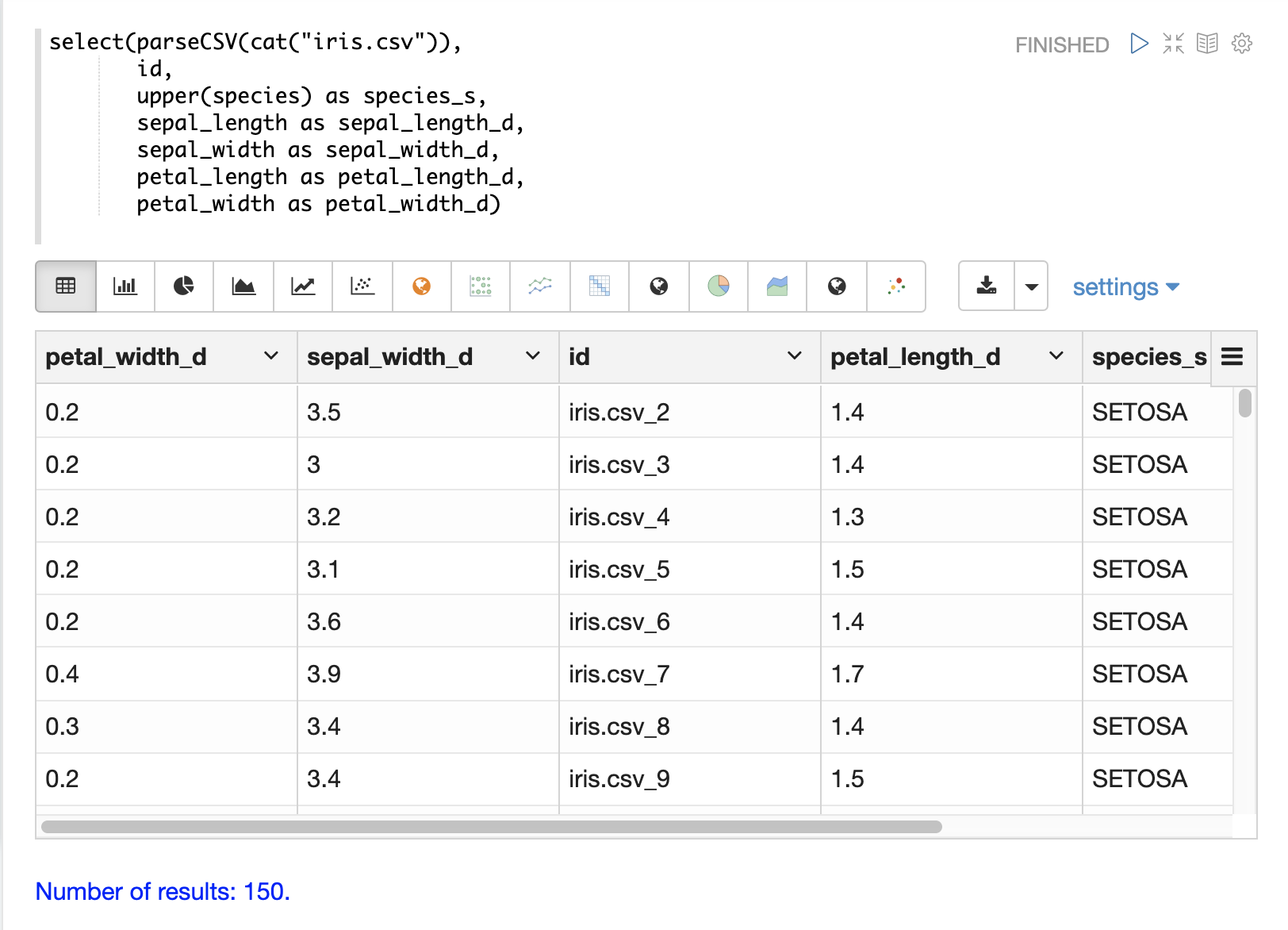
下面的示例显示了 split 函数,该函数在分隔符上拆分字段。这可以用于从具有内部分隔符的字段创建多值字段。
下面的示例演示了直接调用 /stream 处理程序的示例
select(parseCSV(cat("iris.csv")),
id,
split(id, "_") as parts_ss,
species as species_s,
sepal_length as sepal_length_d,
sepal_width as sepal_width_d,
petal_length as petal_length_d,
petal_width as petal_width_d)当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"petal_width_d": "0.2",
"sepal_width_d": "3.5",
"id": "iris.csv_2",
"petal_length_d": "1.4",
"species_s": "setosa",
"sepal_length_d": "5.1",
"parts_ss": [
"iris.csv",
"2"
]
},
{
"petal_width_d": "0.2",
"sepal_width_d": "3",
"id": "iris.csv_3",
"petal_length_d": "1.4",
"species_s": "setosa",
"sepal_length_d": "4.9",
"parts_ss": [
"iris.csv",
"3"
]
}]}}可以使用 valueAt 函数从拆分数组中选择特定索引。
过滤结果
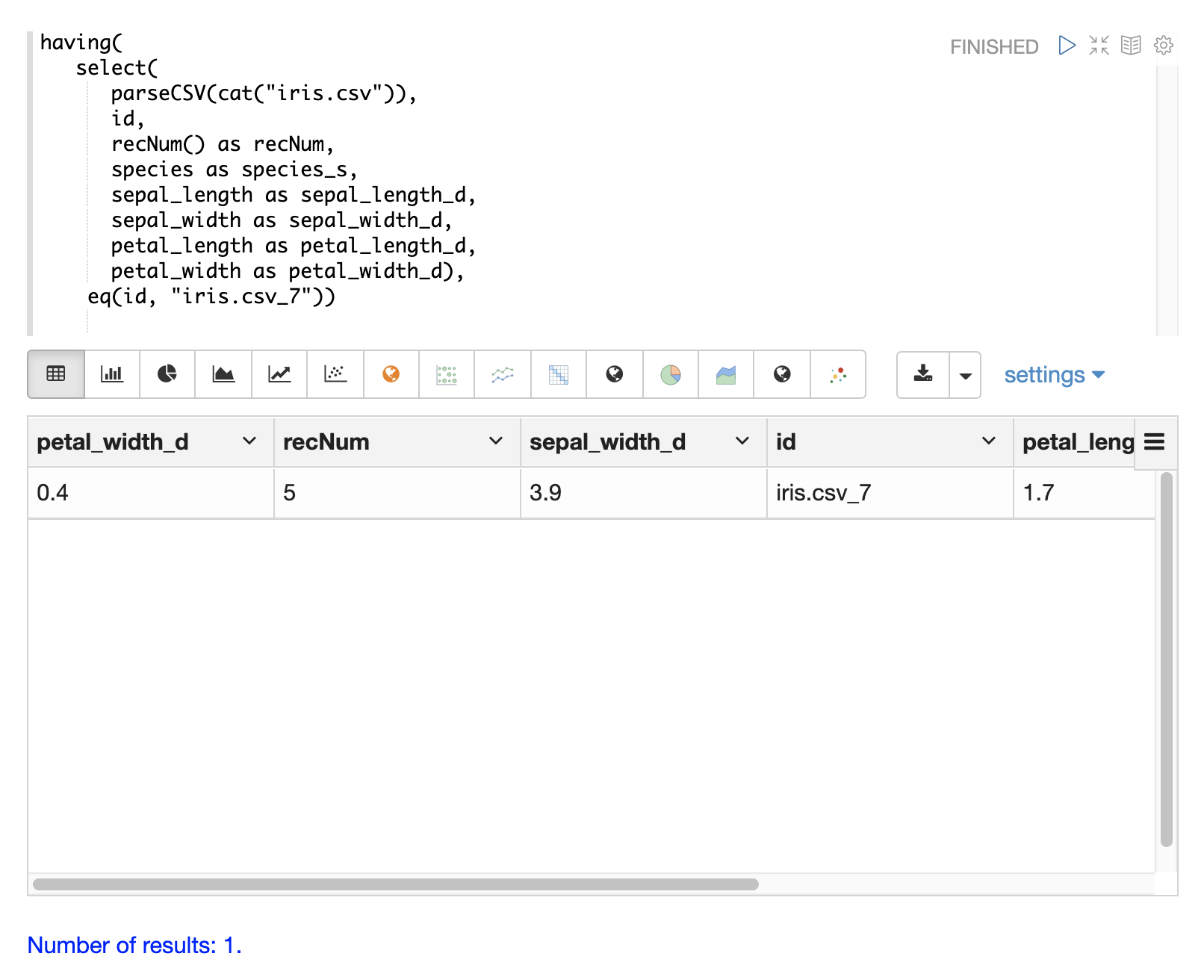
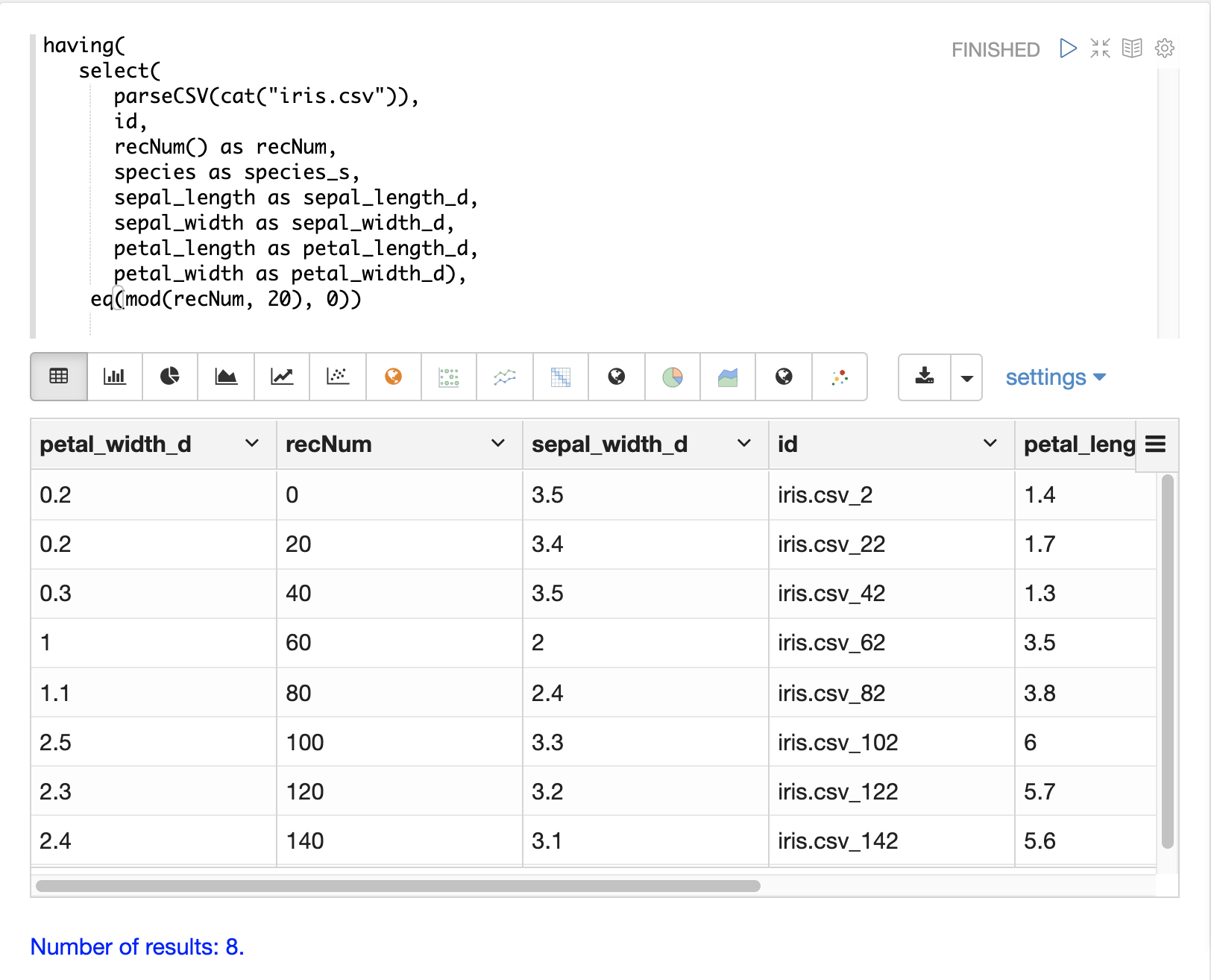
可以使用 having 函数来过滤记录。过滤可用于在索引之前系统地探索特定的记录集,或过滤发送进行索引的记录。having 函数包装另一个流,并将布尔函数应用于每个元组。如果布尔逻辑函数返回 true,则返回元组。
支持以下布尔函数:eq、gt、gteq、lt、lteq、matches、and、or、not、notNull、isNull。
下面是一些使用 having 函数过滤记录的策略。
处理 Null 值
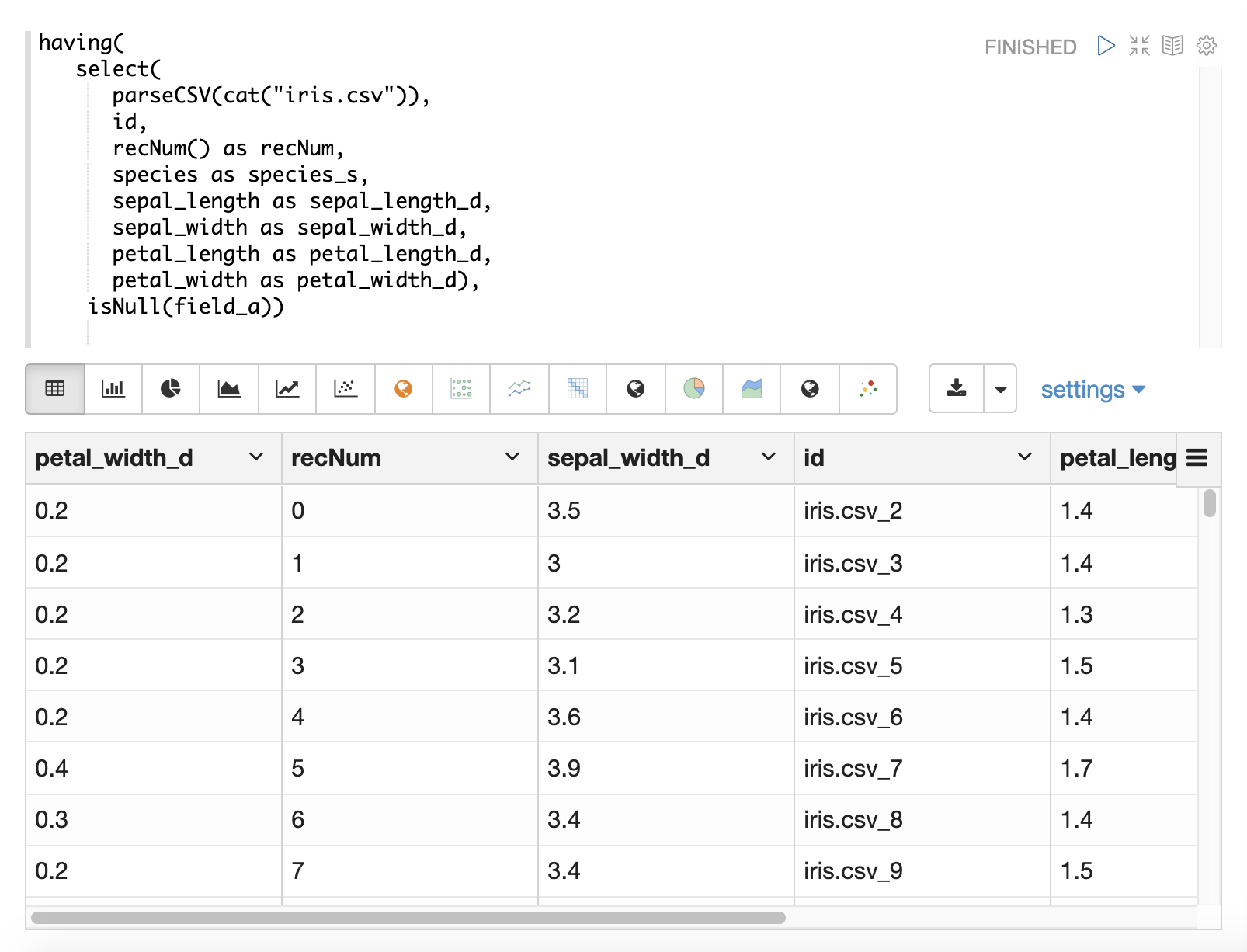
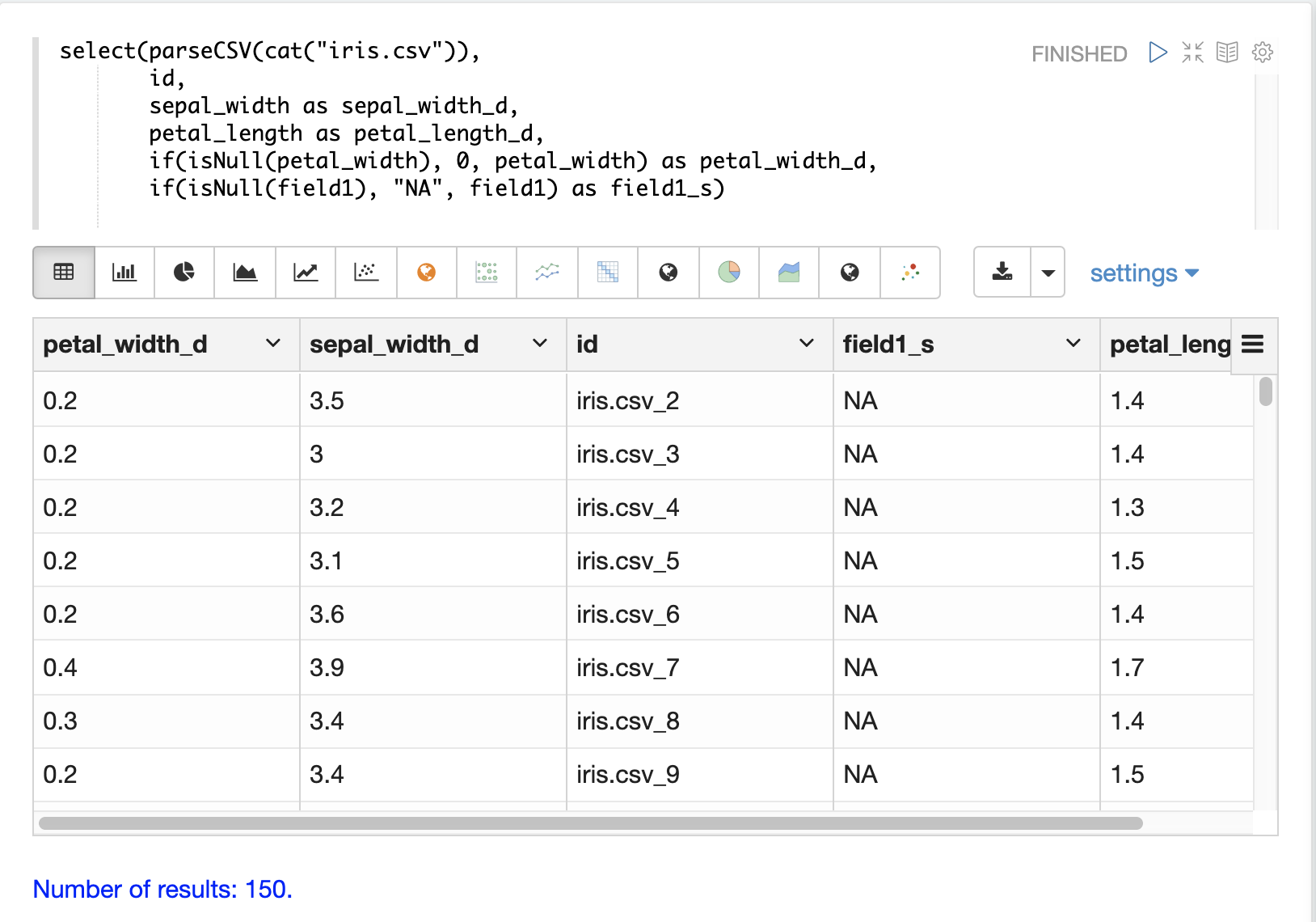
在大多数情况下,无需直接处理 null 值,除非在加载期间需要特定的逻辑来处理 null 值。
select 函数不会输出包含 null 值的字段。这意味着当在数据中遇到 null 值时,这些字段不会包含在元组中。
如果字符串操作函数遇到 null 值,它们都会返回 null。这意味着 null 值将传递到 select 函数,并且带有 null 值的字段将简单地从记录中删除。
在某些情况下,直接过滤或替换 null 值可能很重要。以下部分介绍了这些场景。

文本分析
可以在 select 函数内部使用 analyze 函数,使用可用的分析器来分析文本字段。analyze 的输出是已分析的标记列表,可以作为多值字段添加到每个元组中。
然后可以将多值字段发送到 Solr 进行索引,或者可以使用 cartesianProduct 函数将标记列表展开为元组流。
analyze 函数有许多有趣的用例
-
在索引之前预览不同分析器的输出。
-
在文档到达索引管道之前,使用 NLP 生成的标记(实体提取、名词短语等)注释文档。这消除了可能也在处理查询的服务器上的繁重的 NLP 处理。它还允许将更多的计算资源应用于 NLP 索引,而不是在搜索集群上可用的资源。
-
使用
cartesianProduct函数,可以将分析后的标记索引为单独的文档,这允许使用 Solr 的聚合和图形表达式搜索和分析分析后的标记。 -
此外,使用
cartesianProduct,可以在索引发生之前直接使用流式表达式聚合、分析和可视化分析后的标记。
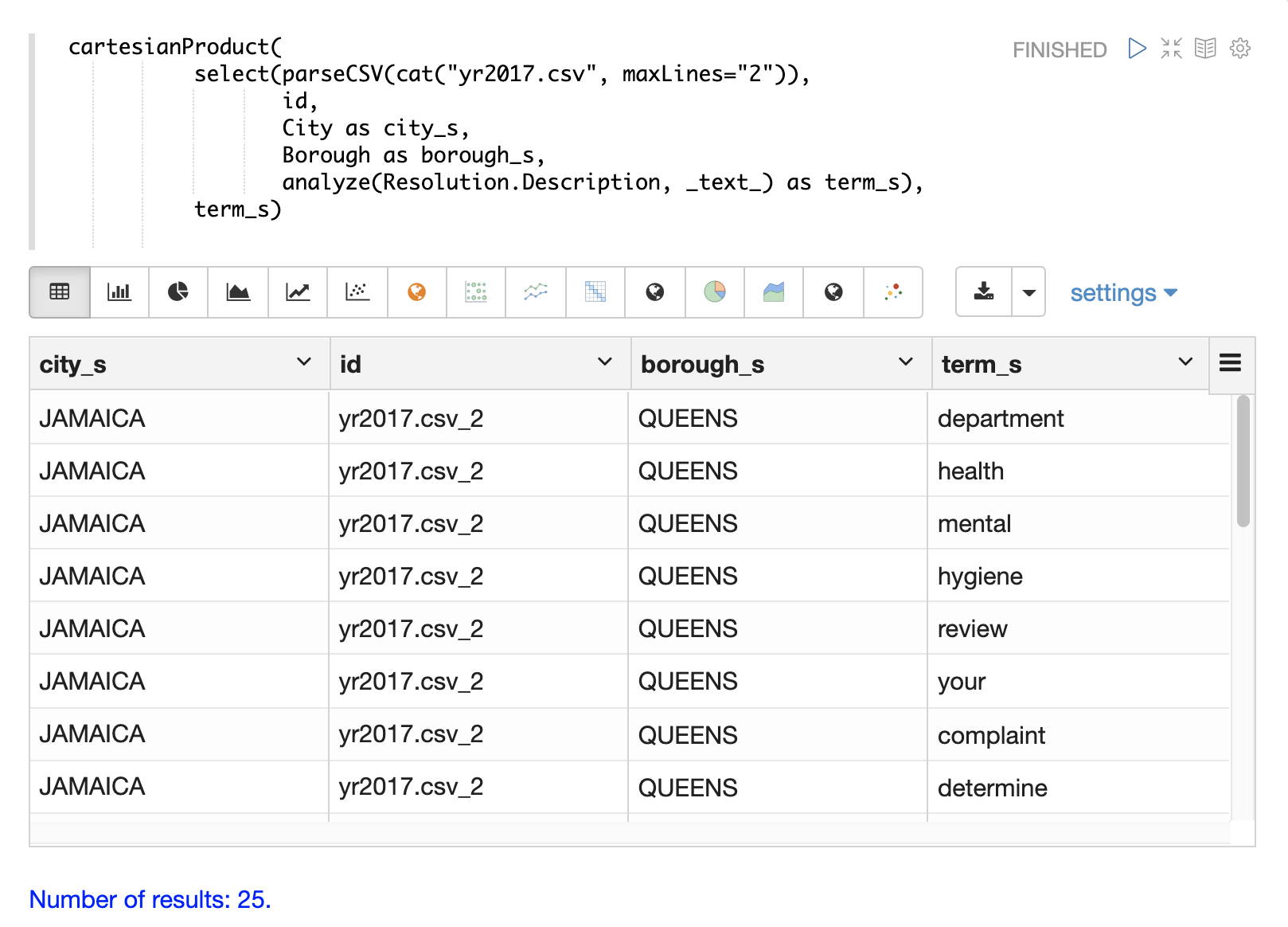
下面是将 analyze 函数应用于元组中 Resolution.Description 字段的示例。使用 _text_ 字段的分析器来分析文本,并将分析后的标记添加到文档的 token_ss 字段中。
select(parseCSV(cat("yr2017.csv", maxLines="2")),
Resolution.Description,
analyze(Resolution.Description, _text_) as tokens_ss)当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"Resolution.Description": "The Department of Health and Mental Hygiene will review your complaint to determine appropriate action. Complaints of this type usually result in an inspection. Please call 311 in 30 days from the date of your complaint for status",
"tokens_ss": [
"department",
"health",
"mental",
"hygiene",
"review",
"your",
"complaint",
"determine",
"appropriate",
"action",
"complaints",
"type",
"usually",
"result",
"inspection",
"please",
"call",
"311",
"30",
"days",
"from",
"date",
"your",
"complaint",
"status"
]
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}下面的示例显示了 cartesianProduct 函数如何将 term_s 字段中分析后的术语展开到它们自己的文档中。请注意,文档中的其他字段会与每个术语一起保留。这允许在单独的文档中索引每个术语,以便可以通过图形表达式或聚合来探索术语与其他字段之间的关系。