结果聚类
|
聚类组件的实现和 API(参数)在 9.0 版本中发生了重大变化。请参考与您的 Solr 版本完全匹配的 Solr 指南。 |
聚类(或聚类分析)插件尝试自动发现相关搜索结果(文档)的组,并为这些组分配人类可读的标签。
Solr 中的聚类算法应用于每次查询的搜索结果中包含的文档——这称为在线聚类。
为给定查询发现的聚类可以被视为动态分面。当常规分面很困难(字段值事先未知)或当查询本质上是探索性的时,这很有益。请查看 Carrot2 项目的演示页面,以查看搜索结果聚类的实际示例(可视化中的组是在右侧的搜索结果中自动发现的,没有涉及外部信息)。
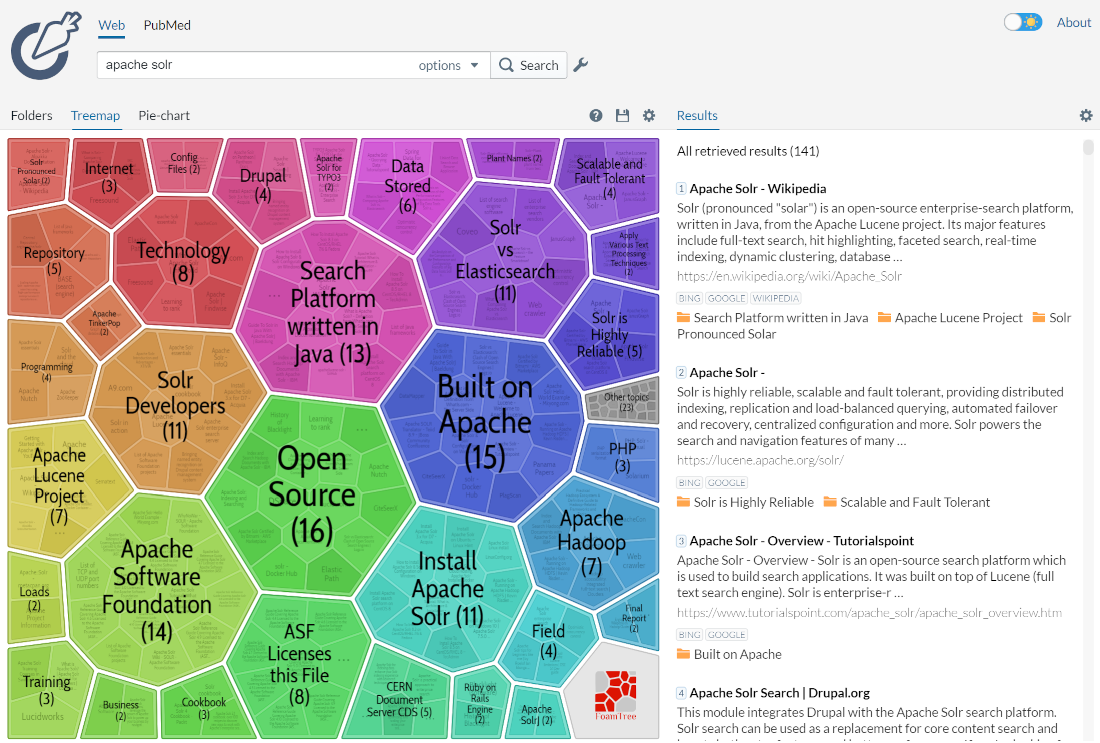
向系统发出的查询是Apache Solr。很明显,分面无法产生类似的组,尽管两种技术的目标相似——让用户探索搜索结果集,并重新措辞查询或将焦点缩小到当前文档的子集。聚类也类似于 结果分组,因为它有助于更深入地查看搜索结果,超越最前面的几个结果。
模块
这是通过 clustering Solr 模块提供的,使用前需要启用该模块。
配置快速入门
聚类扩展作为搜索组件工作。它需要在 solrconfig.xml 中声明和配置,例如
<searchComponent class="org.apache.solr.handler.clustering.ClusteringComponent" name="clustering">
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.fields">title, content</str>
<str name="clustering.algorithm">Lingo</str>
</lst>
</searchComponent>上面声明了具有单个引擎的聚类组件——可以声明多个引擎并在运行时切换。我们稍后将回到如何配置引擎的细节。
聚类组件必须附加到 SearchHandler,并通过属性 clustering 显式启用。重要的是将其附加为处理器管道中的最后一个组件,如下所示
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<bool name="clustering">true</bool>
<str name="clustering.engine">lingo</str>
</lst>
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>如上面的示例所示,一旦附加,聚类将自动对所有匹配搜索处理程序查询的文档执行。聚类扩展将考虑引擎的 clustering.fields 参数中列出的所有文本字段,并生成一个名为 clusters 的响应部分,其中包含已发现的组结构,例如(为简洁起见,使用 JSON 响应):
{
"clusters": [
{
"labels": ["Memory"],
"score": 6.80,
"docs":[ "0579B002",
"EN7800GTX/2DHTV/256M",
"TWINX2048-3200PRO",
"VDBDB1A16",
"VS1GB400C3"]},
{
"labels":["Coins and Notes"],
"score":28.560285143284457,
"docs":["EUR",
"GBP",
"NOK",
"USD"]},
{
"labels":["TFT LCD"],
"score":15.355729924203429,
"docs":["3007WFP",
"9885A004",
"MA147LL/A",
"VA902B"]}
]
}每个群集的 labels 元素是一个动态发现的短语,它描述并适用于 docs 元素下的所有文档标识符。
Solr 分布式示例
Solr 附带的“techproducts”示例已预先配置了结果聚类所需的所有组件,但默认情况下它们处于禁用状态。
要启用聚类组件扩展和配置为使用它的专用搜索处理程序,请在运行示例时指定一个 JVM 系统属性
bin/solr start -e techproducts -Dsolr.clustering.enabled=true现在,您可以尝试在浏览器中打开以下 URL 来尝试聚类处理程序
http://localhost:8983/solr/techproducts/clustering?q=*:*&rows=100&wt=xml
输出的 XML 应包含搜索命中结果,并在末尾包含一个自动发现的群集数组,类似于此处显示的输出
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">299</int>
</lst>
<result name="response" numFound="32" start="0" maxScore="1.0">
<doc>
<str name="id">GB18030TEST</str>
<str name="name">Test with some GB18030 encoded characters</str>
<arr name="features">
<str>No accents here</str>
<str>这是一个功能</str>
<str>This is a feature (translated)</str>
<str>这份文件是很有光泽</str>
<str>This document is very shiny (translated)</str>
</arr>
<float name="price">0.0</float>
<str name="price_c">0,USD</str>
<bool name="inStock">true</bool>
<long name="_version_">1448955395025403904</long>
<float name="score">1.0</float>
</doc>
<!-- more search hits, omitted -->
</result>
<arr name="clusters">
<lst>
<arr name="labels">
<str>DDR</str>
</arr>
<double name="score">3.9599865057283354</double>
<arr name="docs">
<str>TWINX2048-3200PRO</str>
<str>VS1GB400C3</str>
<str>VDBDB1A16</str>
</arr>
</lst>
<lst>
<arr name="labels">
<str>iPod</str>
</arr>
<double name="score">11.959228467119022</double>
<arr name="docs">
<str>F8V7067-APL-KIT</str>
<str>IW-02</str>
<str>MA147LL/A</str>
</arr>
</lst>
<!-- More clusters here, omitted. -->
<lst>
<arr name="labels">
<str>Other Topics</str>
</arr>
<double name="score">0.0</double>
<bool name="other-topics">true</bool>
<arr name="docs">
<str>adata</str>
<str>apple</str>
<str>asus</str>
<str>ati</str>
<!-- other unassigned document IDs here -->
</arr>
</lst>
</arr>
</response>为此查询 (*:*) 发现的几个群集将所有搜索命中结果分为不同的类别:DDR、iPod、硬盘驱动器等。每个群集都有一个标签和分数,表示群集的“质量”。分数是特定于算法的,并且仅与同一组中其他群集的分数相关时才有意义。换句话说,如果群集 A 的分数高于群集 B,则群集 A 的质量应该更好(具有更好的标签和/或更连贯的文档集)。每个群集都有一个属于它的文档标识符数组。这些标识符对应于模式中声明的 uniqueKey 字段。
有时,群集标签可能没有多大意义(这取决于许多因素 - 群集字段中的文本、文档数量、算法参数)。此外,某些文档可能会被遗漏,根本不会被聚类;这些文档将被分配到综合的 *其他主题* 组,并用 other-topics 属性设置为 true 来标记(有关示例,请参见上面的 XML 转储)。其他主题组的分数为零。
配置
组件配置
以下属性控制 ClusteringComponent 的状态。
clustering-
可选
默认值:
false即使正确声明并附加到搜索处理程序,该组件默认情况下也会被禁用。必须将
clustering属性设置为true才能启用它。这可以通过在搜索处理程序中设置默认参数来完成,如下节所述。 clustering.engine-
可选
默认值:请参阅说明
声明要使用的引擎。如果不存在,则使用第一个声明的活动引擎。
聚类引擎
solrconfig.xml 中聚类组件的声明必须包括一个或多个名为 引擎 的预定义配置。例如,考虑以下配置:
<searchComponent class="org.apache.solr.handler.clustering.ClusteringComponent" name="clustering">
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">title, content</str>
</lst>
<lst name="engine">
<str name="name">stc</str>
<str name="clustering.algorithm">STC</str>
<str name="clustering.fields">title</str>
</lst>
</searchComponent>这声明了两个单独的引擎(lingo 和 stc):这些配置具有不同的聚类算法和一组不同的聚类文档字段。可以通过在运行时(通过 URL)传递 clustering.engine=name 参数或作为搜索处理程序配置中的默认值来选择活动引擎,如下所示:
<requestHandler name="/clustering" class="solr.SearchHandler">
<lst name="defaults">
<!-- Clustering component enabled. -->
<bool name="clustering">true</bool>
<str name="clustering.engine">stc</str>
<!-- Cluster the top 100 search results - bump up the 'rows' parameter. -->
<str name="rows">100</str>
</lst>
<!-- Append clustering at the end of the list of search components. -->
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>聚类引擎配置参数
可以使用下面描述的多个参数来配置每个声明的引擎。
clustering.fields-
必需
默认值:无
一个以逗号(或空格)分隔的文本字段列表,其中应包含用于聚类的文本内容。必须至少提供一个字段。这些字段与搜索处理程序的
fl参数分开,因此不必在响应中包含聚类字段。 clustering.algorithm-
必需
默认值:无
聚类算法是实际的逻辑(实现),用于发现文档之间的关系并形成人类可读的群集标签。此参数设置此引擎将要使用的聚类算法的名称。通过 Carrot2 定义的服务扩展将算法提供给 Solr。默认情况下,应提供以下开源算法:
Lingo、STC、二分 K 均值。商业聚类算法Lingo3G插入到相同的扩展点,如果它在类路径上可用,则可以使用它。
clustering.maxLabels-
可选
默认值:无
返回的最大群集标签数(如果算法返回更多标签,则列表将被截断)。默认情况下,将返回所有标签。
clustering.includeSubclusters-
可选
默认值:无
如果为
true,则会在支持分层聚类的算法的响应中包含子群集。false只会导致返回顶级群集。 clustering.includeOtherTopics-
可选
默认值:
true如果为
true,则会形成并返回一个名为“其他主题”的综合群集,其中包含所有未分配给任何其他群集的文档。如果不需要此综合群集,则可以将其设置为false。 clustering.resources-
可选
默认值:无
特定于算法的资源和配置文件(停用词、其他词汇资源、默认设置)的位置。此属性默认为
null,所有资源都从其各自算法的默认资源池(JAR)读取。如果此属性不为空,则它相对于 Solr 核心的配置目录解析。此参数只能在 Solr 启动期间应用,不能按请求重写。
还有更多适用于引擎配置的属性。我们将在后续的功能部分中描述这些属性。
完整字段和查询上下文(片段)聚类
聚类算法可以消耗字段的完整内容,或者仅消耗查询匹配区域周围的左右上下文(所谓的片段)。与直觉相反,即使向算法提供的数据较少,使用查询上下文也可以提高聚类的质量。这通常是由于片段更关注围绕查询的短语和术语的事实,并且算法具有更好的数据信噪比。
我们建议在字段包含大量内容时使用查询上下文(这会影响聚类性能)。
以下三个属性控制是处理上下文还是完整内容,以及如何形成用于聚类的片段。
clustering.preferQueryContext-
可选
默认值:无
如果为
true,则引擎将尝试提取查询匹配区域周围的上下文,并将这些上下文用作聚类算法的输入。 clustering.contextSize-
可选
默认值:无
上下文检索算法(内部突出显示器)创建的每个片段的最大大小(以字符为单位)。
clustering.contextCount-
可选
默认值:无
来自单个字段的不同、非连续片段的最大数量。
默认聚类语言
Carrot2 中聚类算法的默认实现(随 Solr 一起提供)内置了对预处理多种语言的支持(词干提取、停用词)。为聚类算法提供一个关于应该使用哪种语言进行聚类的提示非常重要。可以通过两种方式完成此操作 - 通过传递默认语言的名称或通过为每个文档提供一个包含语言的字段。以下两个引擎配置参数控制此操作
clustering.language-
可选
默认值:
English用于聚类的默认语言的名称。提供的语言必须可用,并且聚类算法必须支持它。
clustering.languageField-
可选
默认值:无
存储文档语言的文档字段的名称。如果文档不存在该字段或该值为空,则使用默认语言。
支持的语言列表可以动态更改(语言通过外部服务提供商扩展加载),并且可能取决于所选的算法(算法可以支持可提供资源的语言子集)。聚类组件将在 Solr 启动时记录所有支持的算法-语言对,因此您可以检查在您的特定 Solr 实例上支持哪些内容。例如:
2020-10-29 [...] Clustering algorithm Lingo3G loaded with support for the following languages: Dutch, English
2020-10-29 [...] Clustering algorithm Lingo loaded with support for the following languages: Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish
2020-10-29 [...] Clustering algorithm Bisecting K-Means loaded with support for the following languages: Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish调整算法设置
Solr 随附的聚类算法使用其默认参数值和语言资源。我们强烈建议为生产用途调整这两者。改进默认语言资源以包含特定文档域常用的单词和短语将显着提高聚类质量。
Carrot2 算法具有广泛的参数集和语言资源调整选项。请参阅最新的项目文档。特别是语言资源部分和每个算法的属性部分。
更改聚类算法参数
可以通过 Solr 参数永久(在引擎的声明中)或按请求(通过 Solr URL 参数)更改聚类算法设置。
例如,让我们假设以下引擎配置:
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
</lst>首先,在Carrot2 文档站点上找到 Lingo 算法的配置参数
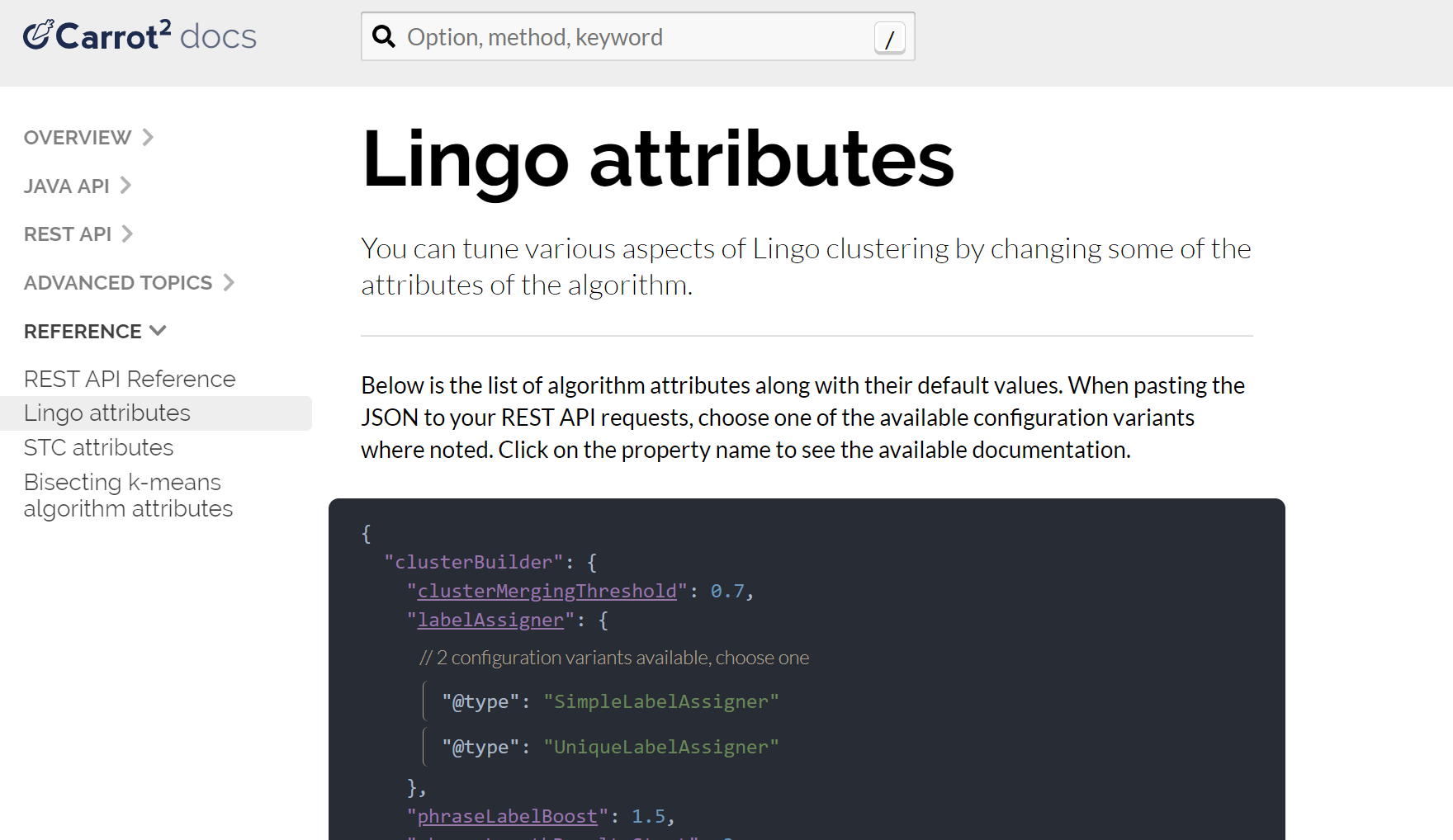
然后找到您要更改的特定设置,并记下该设置的 REST API 路径(在本例中,参数为 minClusterSize,其路径为 preprocessing.documentAssigner.minClusterSize)

现在将完整的路径-值对添加到引擎的配置中:
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
<int name="preprocessing.documentAssigner.minClusterSize">3</int>
</lst>以下规则适用:
-
参数的类型必须与 Carrot2 规范中列出的类型一致。
-
如果将参数添加到
solrconfig.xml中的引擎配置中,则必须重新加载核心才能使更改生效。或者,通过请求 URL 传递参数,以按请求动态更改内容。例如,如果您正在运行“techproducts”示例,这将仅将群集削减为那些包含至少三个文档的群集:http://localhost:8983/solr/techproducts/clustering?q=*:*&rows=100&wt=json&preprocessing.documentAssigner.minClusterSize=3 -
对于复杂类型,具有实例化类型名称的参数键必须位于其自身任何参数之前。
自定义语言资源
聚类算法依赖于特定语言和领域的语言资源,以提高聚类的质量(通过丢弃特定领域的噪音和样板语言)。
默认情况下,语言资源从引擎声明的算法默认 JAR 中读取。您可以通过指定 clustering.resources 参数来传递这些资源的自定义位置。此参数的值解析为相对于 Solr 核心配置目录的位置。例如,以下定义
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
<str name="clustering.resources">lingo-resources</str>
</lst>将导致以下日志条目和预期的资源位置
Clustering algorithm resources first looked up relative to: [.../example/techproducts/solr/techproducts/conf/lingo-resources]开始调整算法资源的最佳方法是从其对应的 Carrot2 JAR 文件(或 Carrot2 发行版)中复制所有默认值。
性能考虑
搜索结果的聚类带来了一些性能方面的考虑
-
获取比平时更多的搜索结果(50、100 或更多文档)的成本,
-
聚类本身带来的额外计算成本。
-
在分布式模式下,用于聚类的文档字段内容是从分片中收集的,这会增加一些额外的网络开销。
对于简单的查询,聚类时间通常会占据主导地位。如果文档字段非常长,则检索存储的内容可能会成为瓶颈。
可以通过几种方式降低聚类的性能影响。
-
聚类更少的数据:使用查询上下文(片段)而不是完整的字段内容(
clustering.preferQueryContext=true)。 -
仅对文档字段的子集执行聚类或管理用于聚类的字段(在索引时添加摘要)以减小输入。
-
调整直接与特定算法相关的性能属性。
-
尝试不同的、更快的算法(STC 而不是 Lingo,Lingo3G 而不是 STC)。
其他资源
以下资源提供了有关 Solr 中聚类组件及其潜在应用的更多信息。
-
Solr 搜索结果的聚类和可视化(柏林 BuzzWords 会议,2011):http://2011.berlinbuzzwords.de/sites/2011.berlinbuzzwords.de/files/solr-clustering-visualization.pdf