日志分析
用户指南的此部分介绍了 Solr 日志分析的入门知识。
| 这是流式表达式和数学表达式可视化指南的附录。下面描述的所有函数都在指南中详细介绍。请参阅入门章节,了解如何开始使用可视化和 Apache Zeppelin。 |
加载
可以使用 Solr 发行版 bin/ 目录中的 bin/solr postlogs 命令行工具,将开箱即用的 Solr 日志格式加载到 Solr 索引中。
Postlogs
postlogs 命令读取 Solr 的日志格式并将其索引到 Solr 集合中。
bin/solr postlogs [选项]
bin/solr postlogs --help
健康检查参数
-url <地址>-
必需
默认值:无
集合的地址,例如 http://localhost:8983/solr/collection1/。
-rootdir <目录>-
必需
默认值:无
日志目录根目录的文件路径:将索引在此目录下找到的所有文件(包括子目录)。如果路径指向单个日志文件,则仅加载该日志文件。
示例:
bin/solr postlogs --url http://localhost:8983/solr/logs --rootdir /var/logs/solrlogs
上面的示例会将 /var/logs/solrlogs 下的所有日志文件索引到基本 URL http://localhost:8983/solr 处的 logs 集合中。
浏览
日志浏览通常是日志分析和可视化的第一步。
在处理不熟悉的安装时,可以使用浏览来了解日志中涵盖了哪些集合、这些集合中有哪些分片和核心,以及对这些集合执行的操作类型。
即使对于熟悉的 Solr 安装,浏览在故障排除时仍然非常重要,因为它通常会发现诸如未知错误或意外管理或索引操作之类的意外情况。
采样
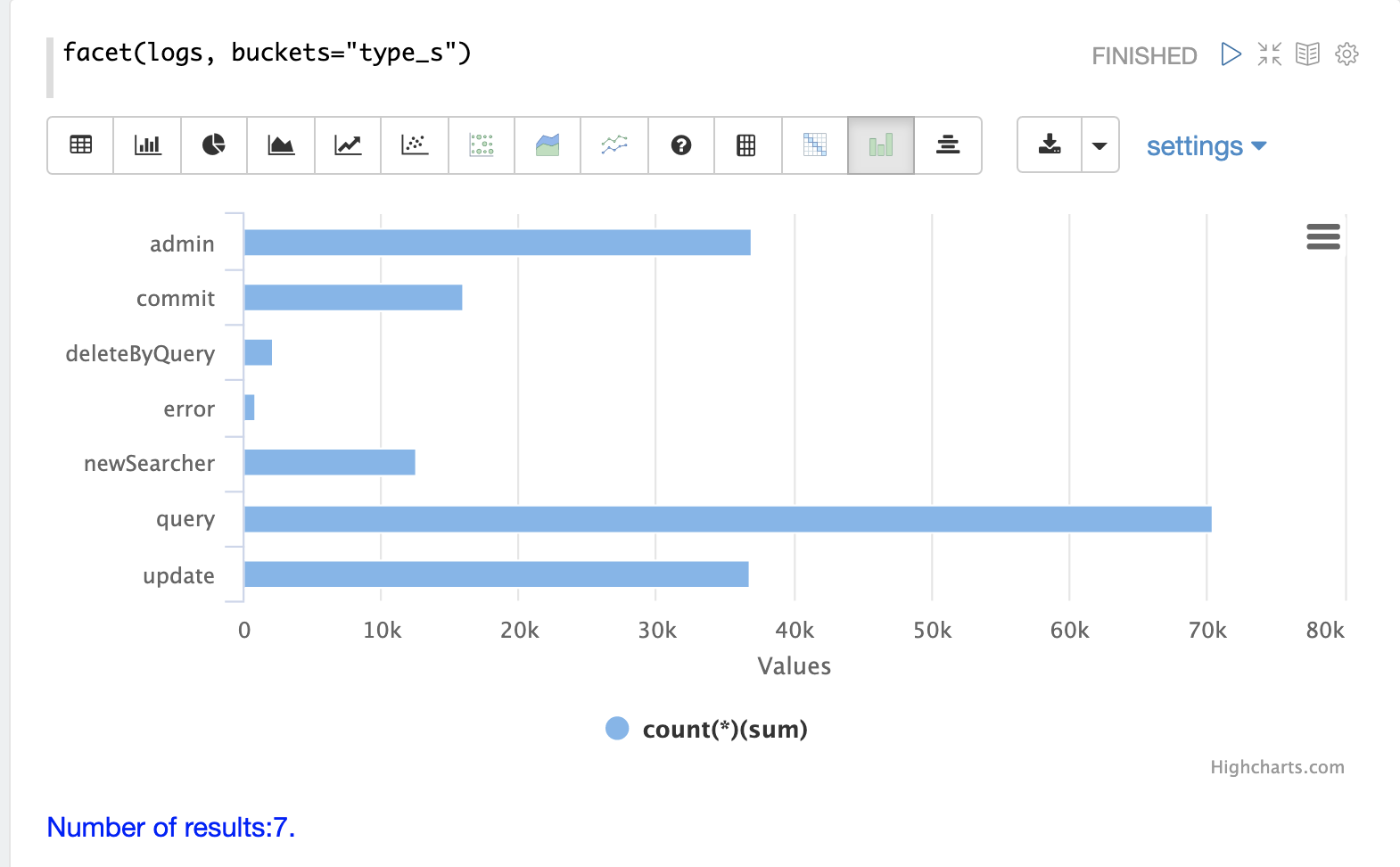
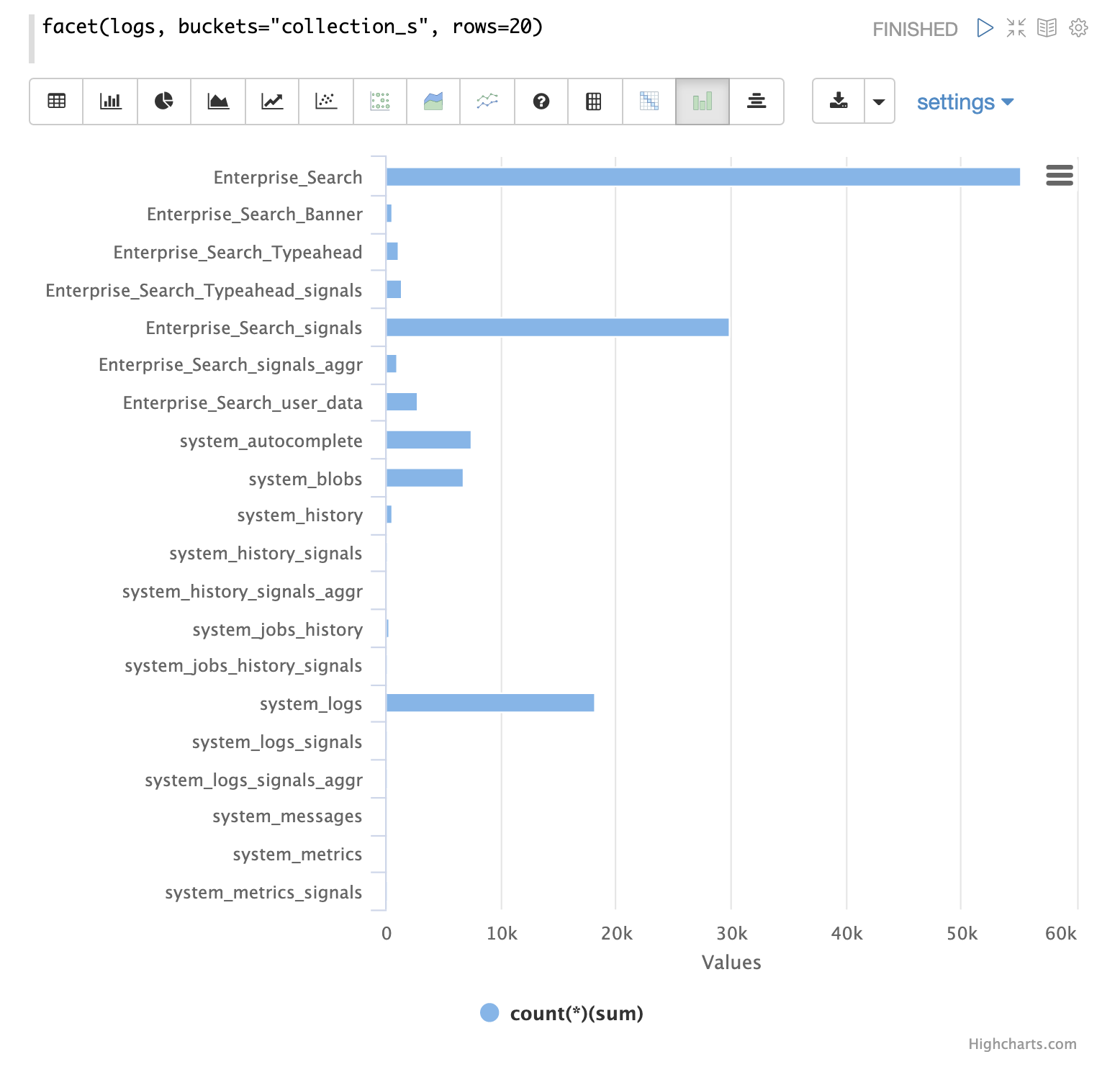
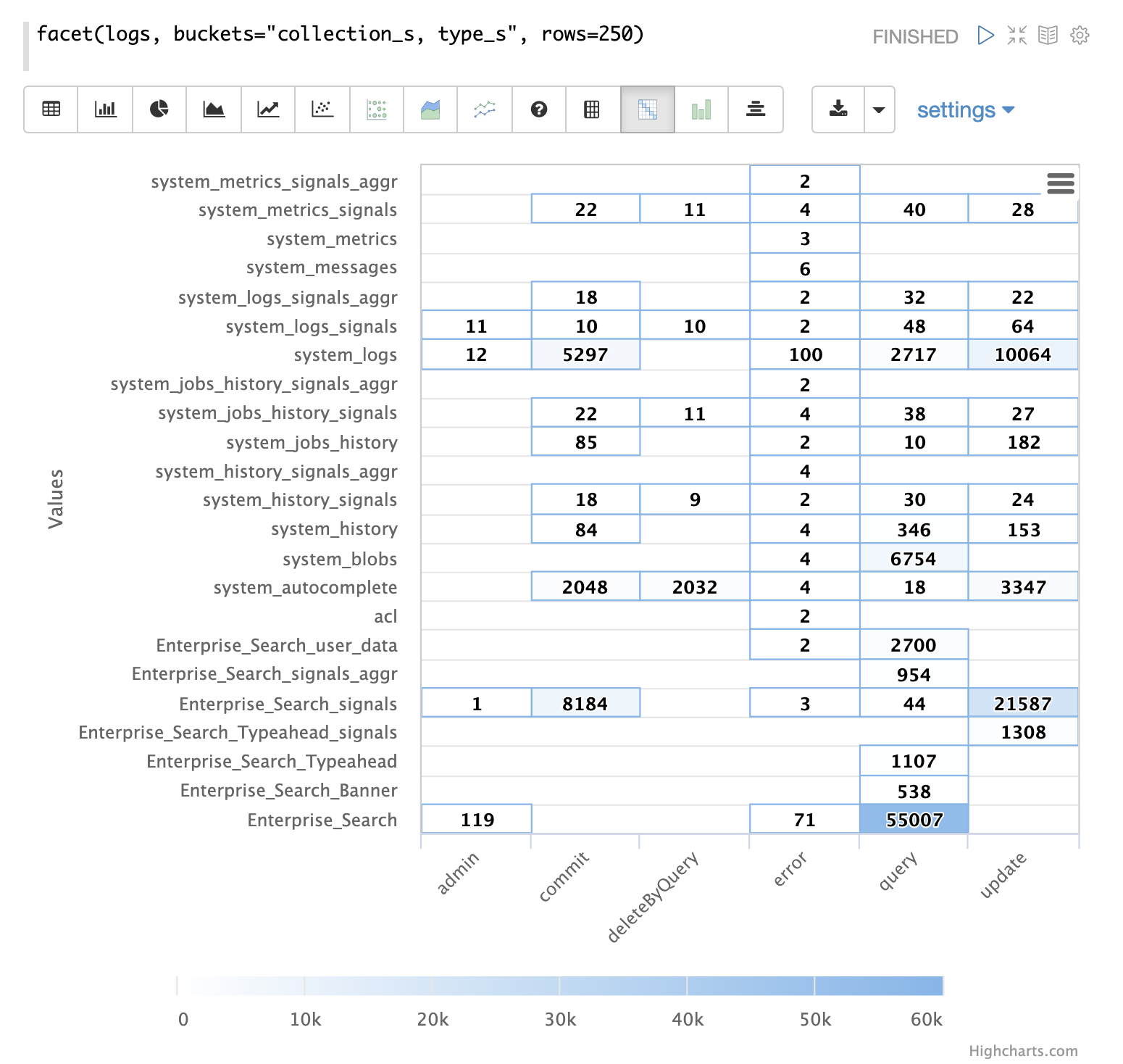
浏览的第一步是从具有 random 函数的 logs 集合中获取随机样本。
在下面的示例中,random 函数使用一个参数运行,该参数是要采样的集合的名称。
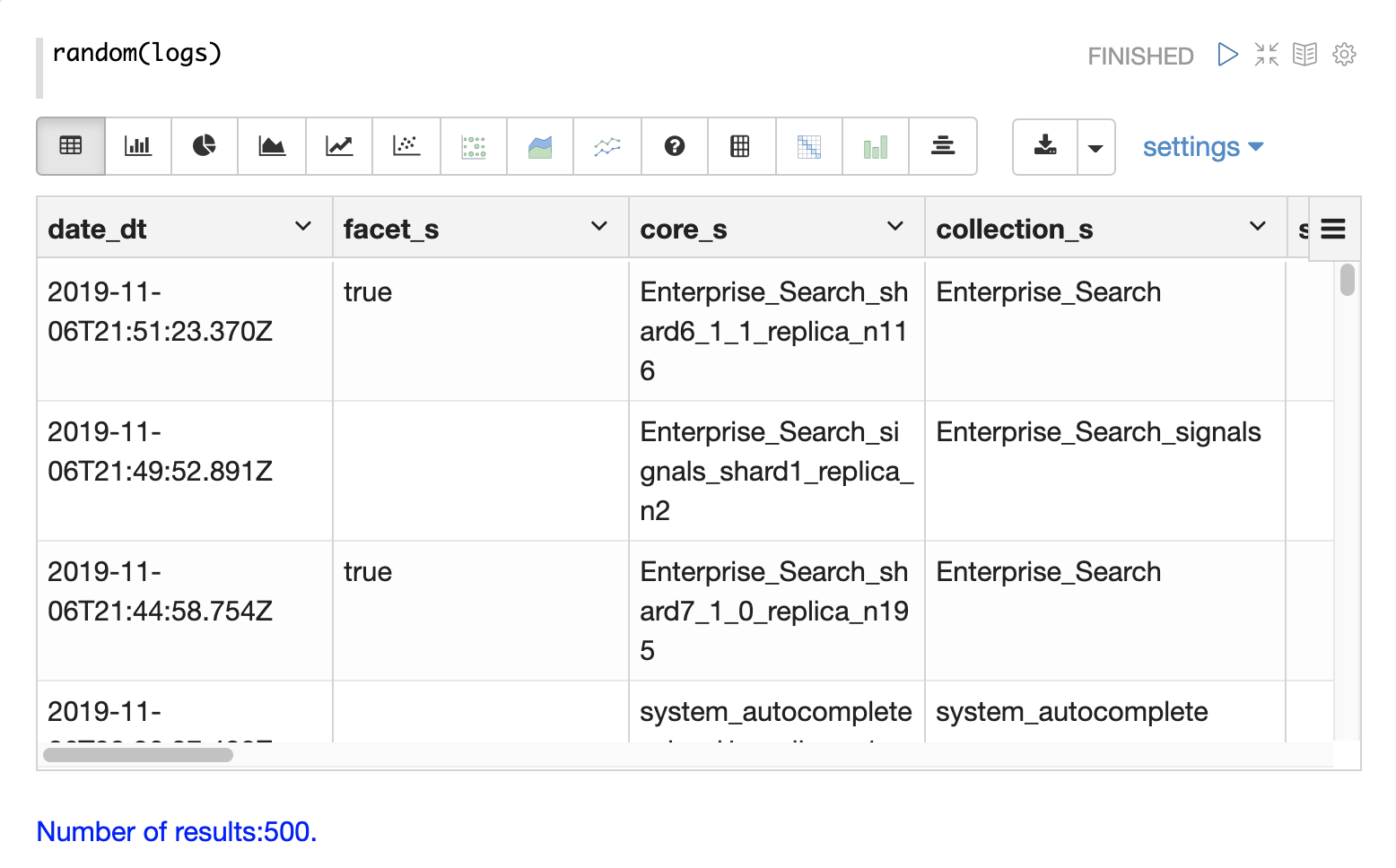
该样本包含 500 个随机记录及其完整的字段列表。通过查看此样本,我们可以快速了解 logs 集合中可用的字段。
时间序列
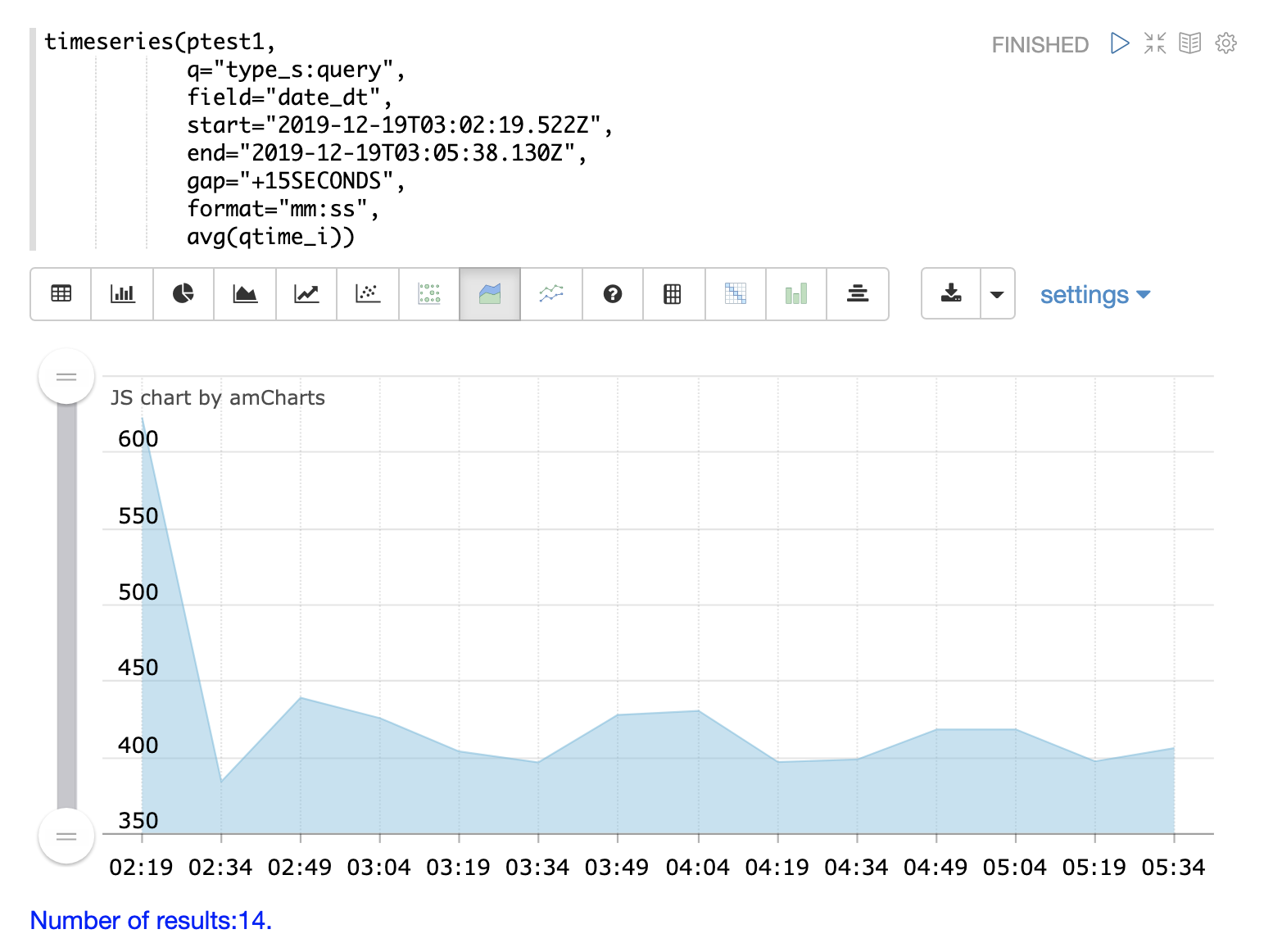
可以使用 timeseries 函数可视化日志的特定时间范围的时间序列。
在下面的示例中,使用时间序列来可视化以 15 秒间隔的日志记录计数。
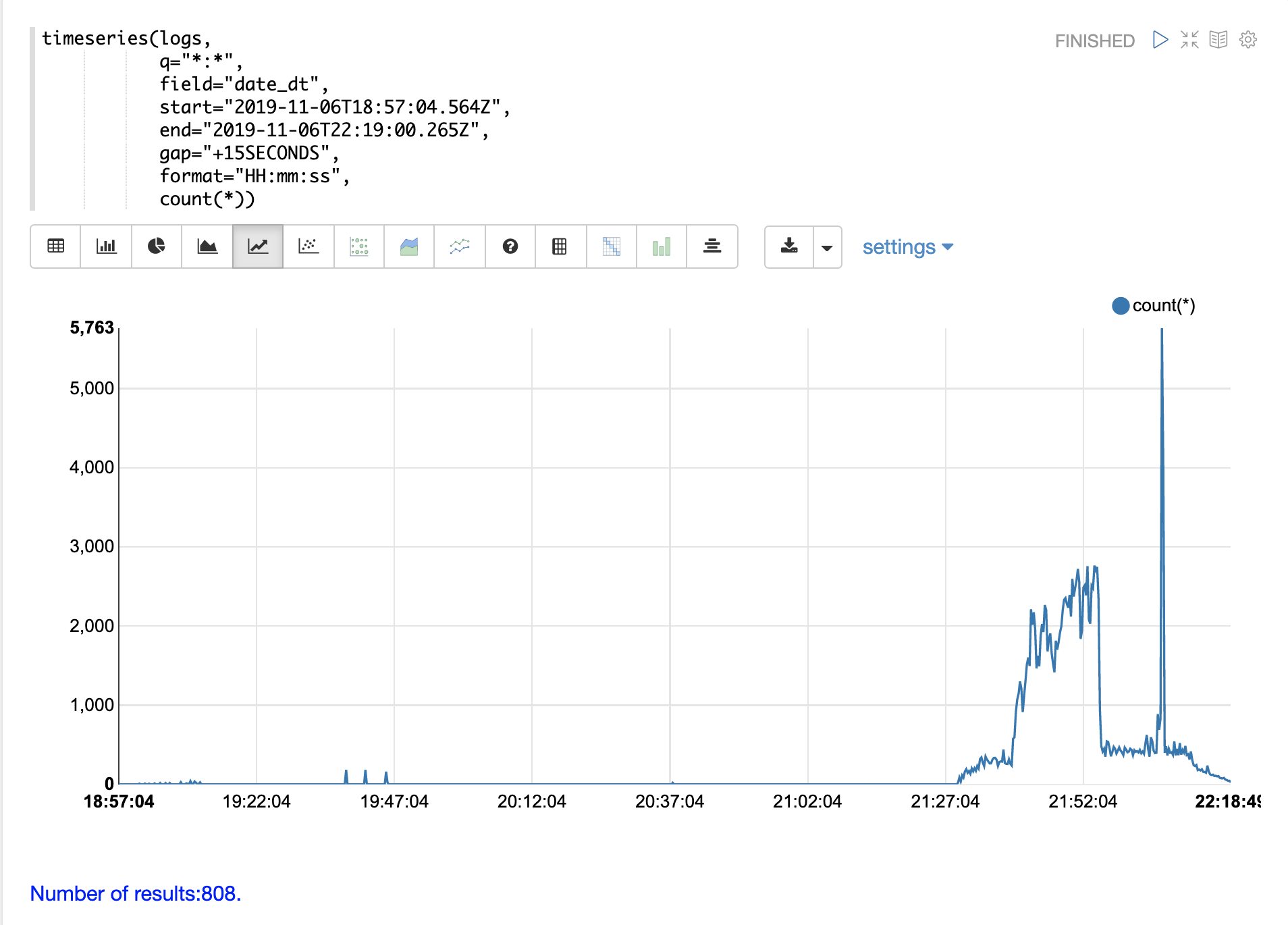
请注意,在 21 小时 27 分钟之前,日志活动非常低。然后,从 27 分钟到 52 分钟之间,会出现日志活动爆发。
接下来是日志活动的大量峰值。
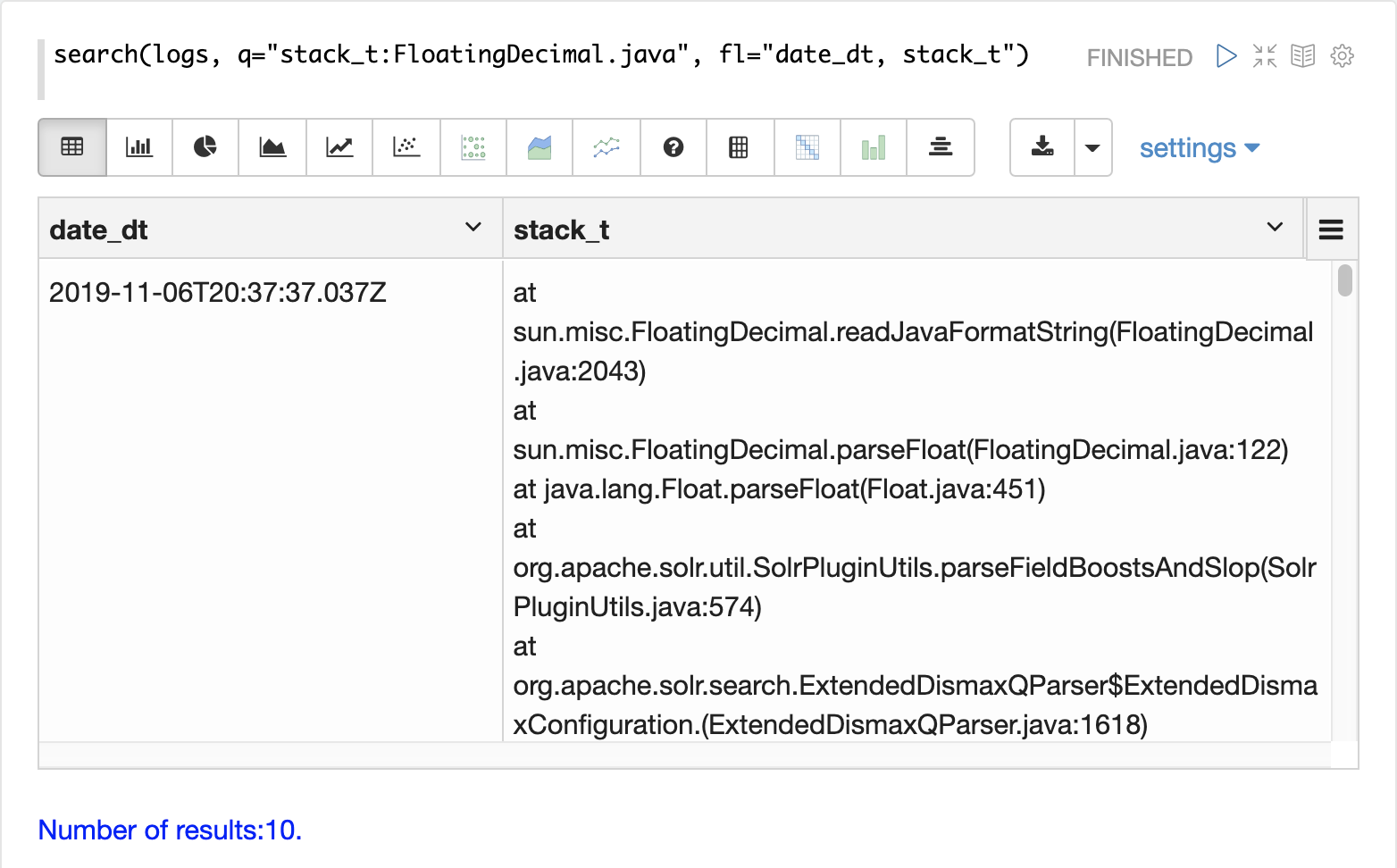
下面的示例通过在 type_s 字段上添加查询来进一步分解,仅可视化日志中的 query 活动。
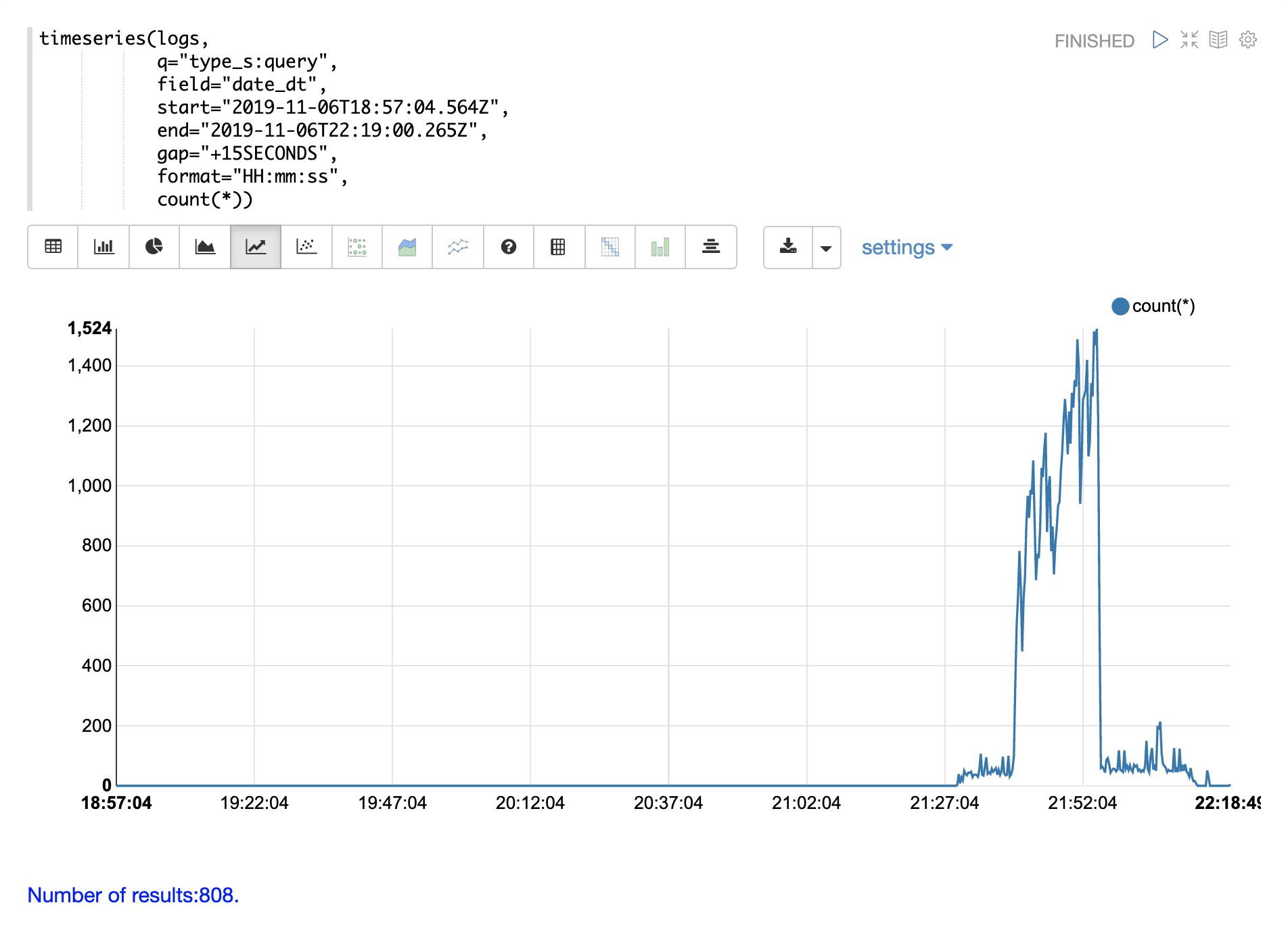
请注意,在 21:27 到 21:52 之间,查询活动占日志记录突发的一半以上。但是,查询活动并不能解释随后的日志活动的大量峰值。
我们可以通过更改搜索以仅包含日志中的 update、commit 和 deleteByQuery 记录来解释该峰值。我们还可以按集合缩小范围,以便知道这些活动发生在何处。
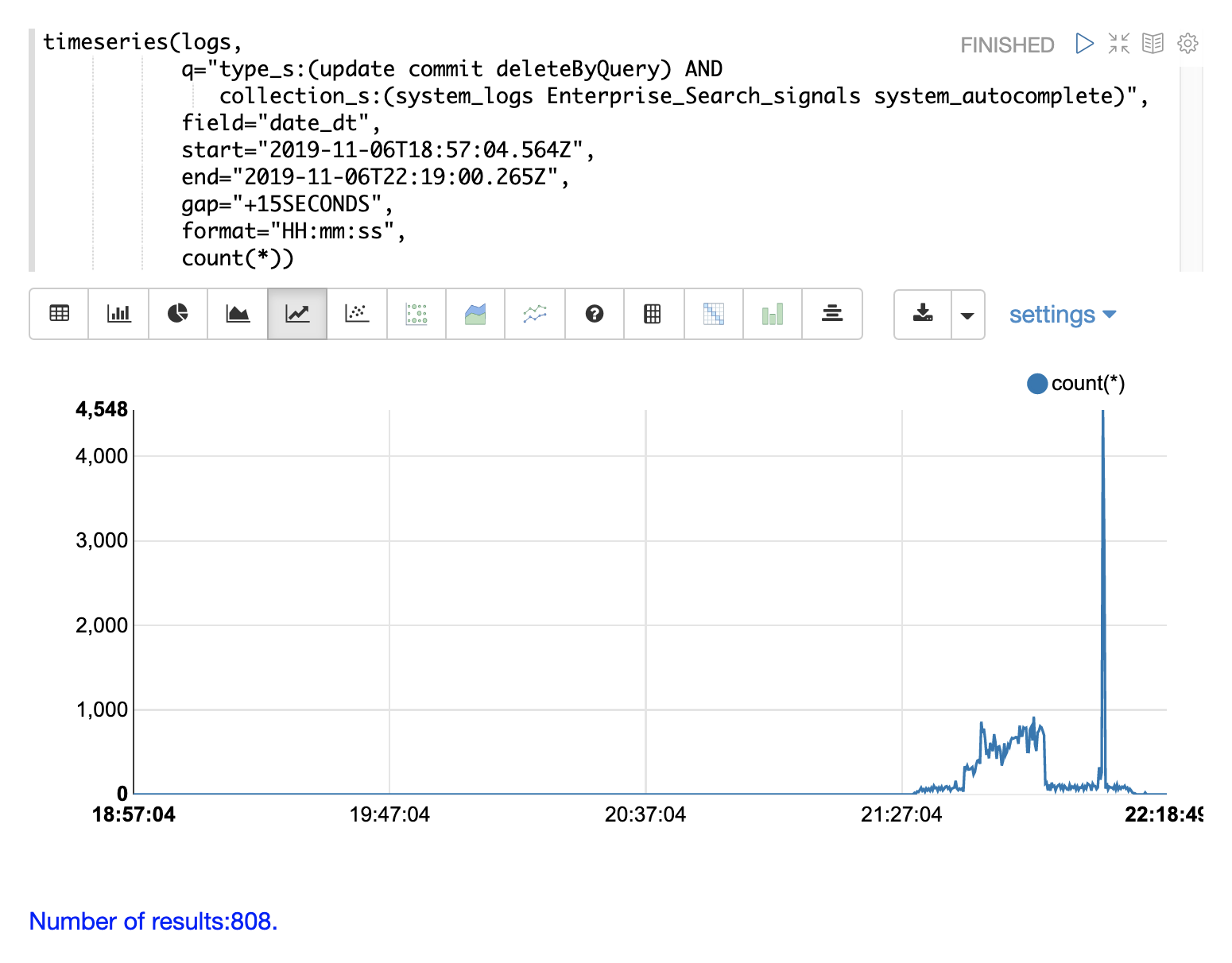
通过各种探索性查询和可视化,我们现在对日志中包含的内容有了更好的了解。
查询计数
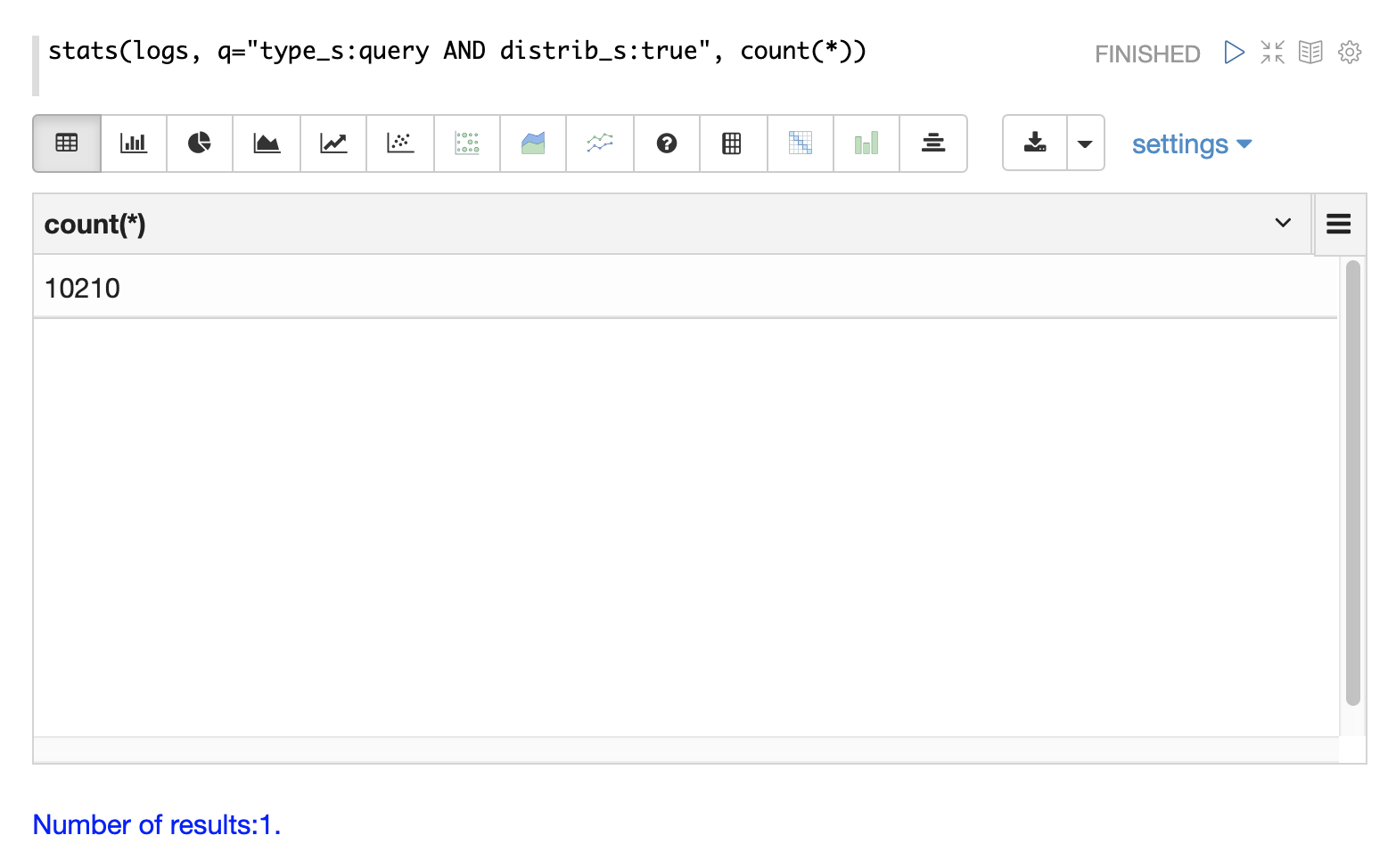
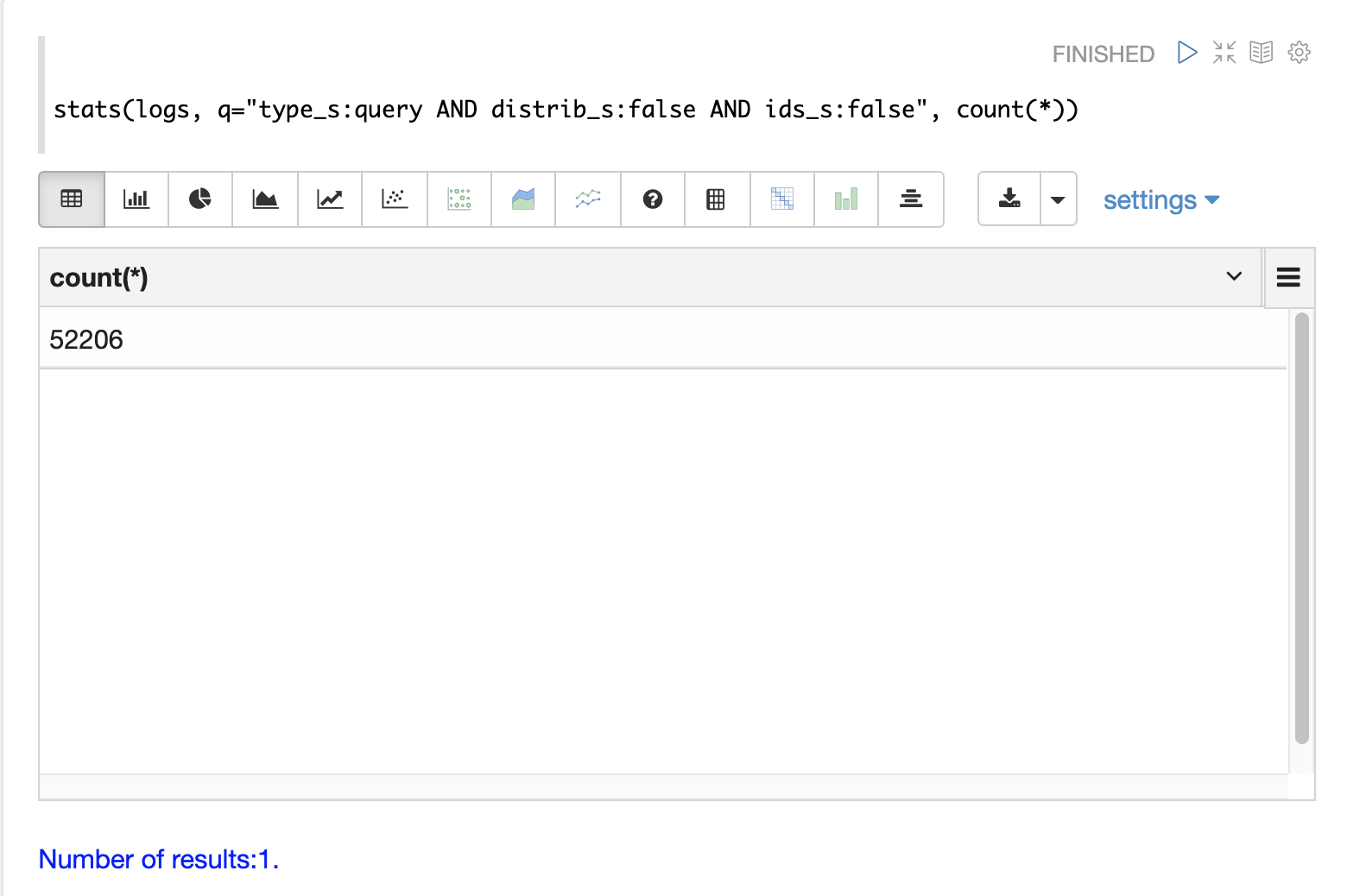
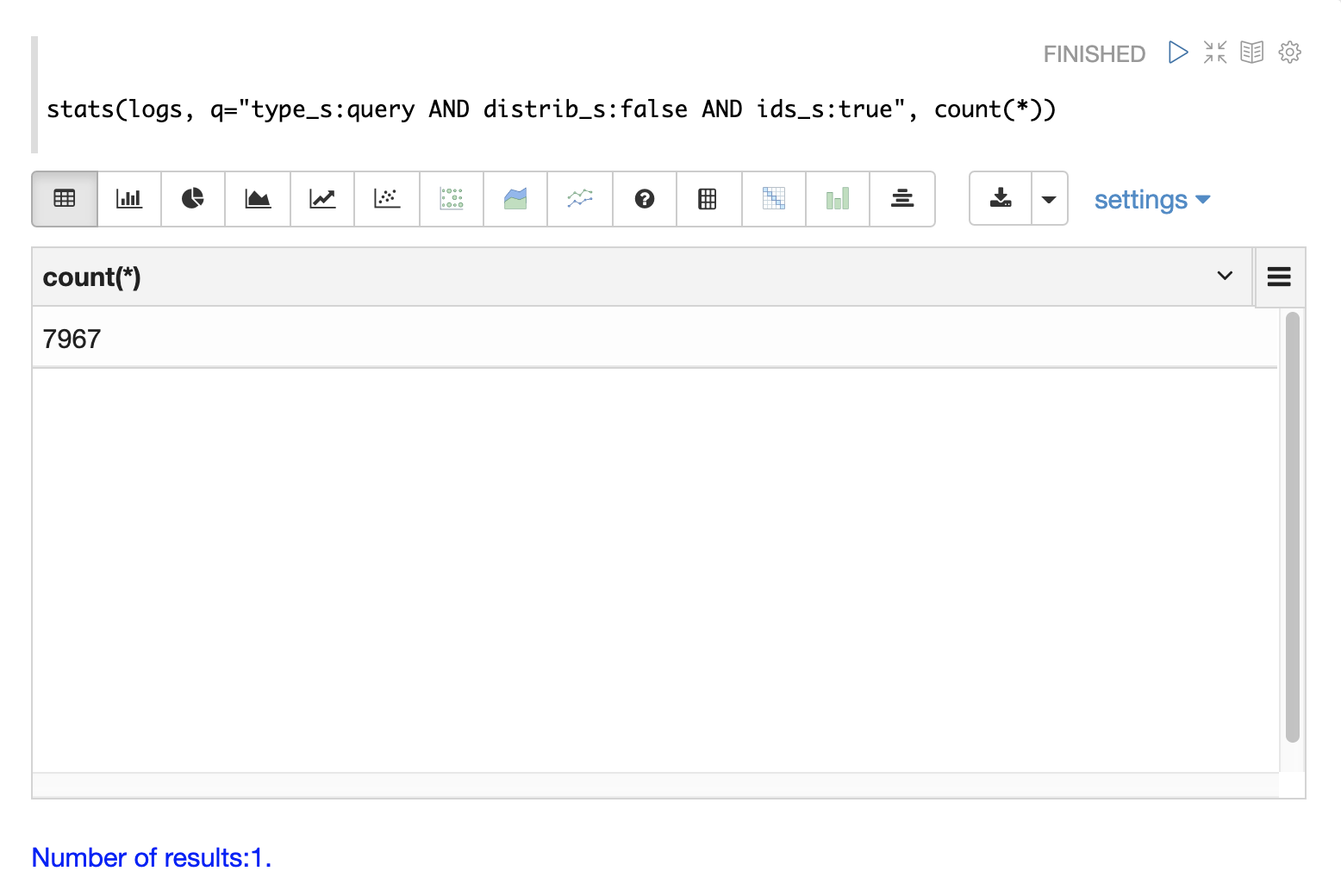
分布式搜索为每个查询生成多个日志记录。顶级分布式查询将有一个 顶级 日志记录,每个分片的一个副本上将有一个 分片级 日志记录。可能还有一组 ids 查询,用于从分片中检索字段以完成结果页。
日志索引中有一些字段可用于区分三种类型的查询记录。
下面的示例使用 stats 函数来计算日志中不同类型的查询记录。相同的查询可以与 search、random 和 timeseries 函数一起使用,以返回特定类型的查询记录的结果。
查询性能
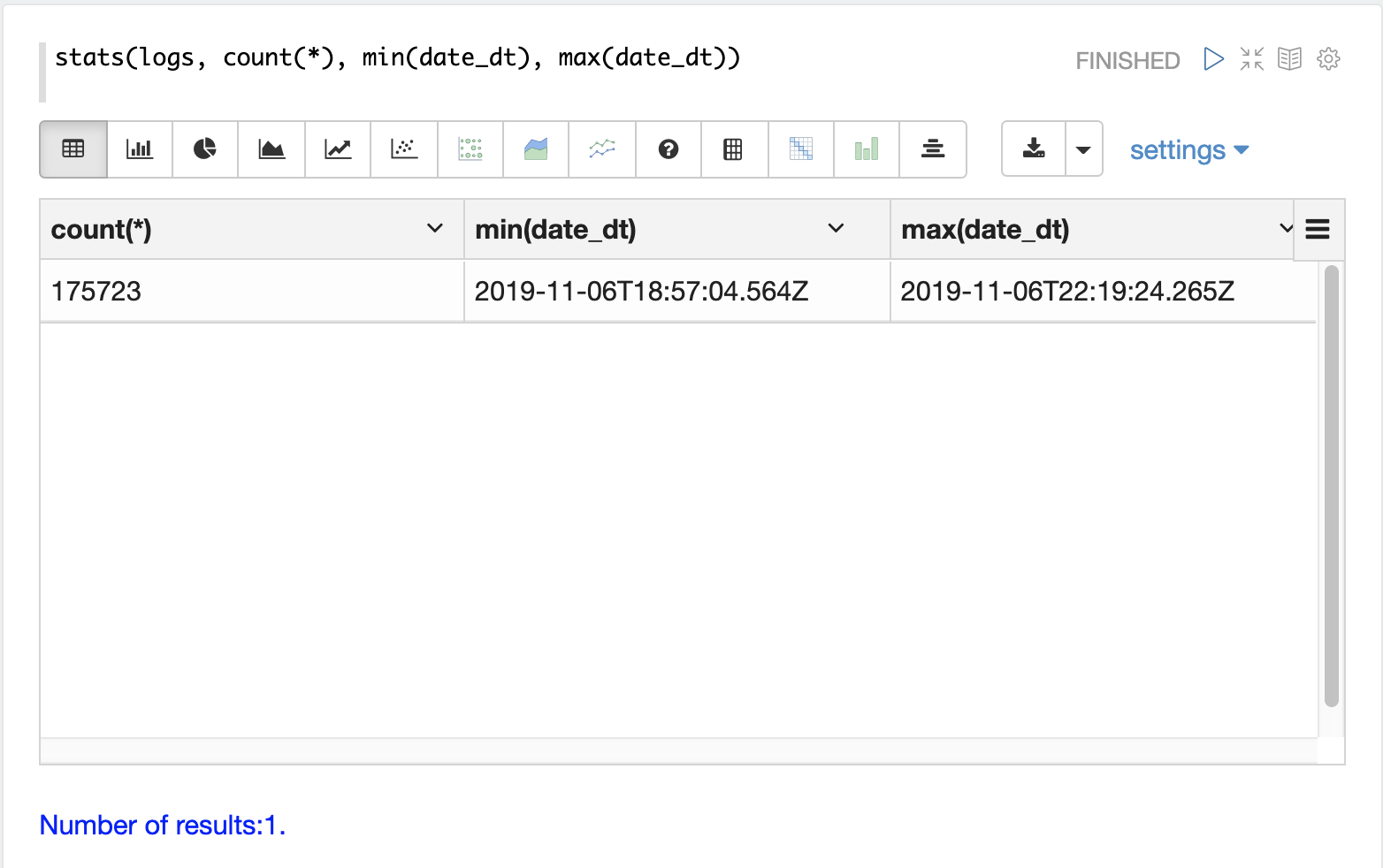
Solr 日志分析的重要任务之一是了解 Solr 集群的性能如何。
qtime_i 字段包含日志记录中的查询时间 (QTime),以毫秒为单位。有许多强大的可视化和统计方法可用于分析查询性能。
QTime 散点图
散点图可用于可视化 qtime_i 字段的随机样本。下面的示例演示了 ptest1 集合的日志记录中 500 个随机样本的散点图。
在此示例中,qtime_i 绘制在 y 轴上,x 轴只是一个序列,用于在图中展开查询时间。
x 字段包含在字段列表中。当 x 包含在字段列表中时,random 函数会自动为 x 轴生成一个序列。 |
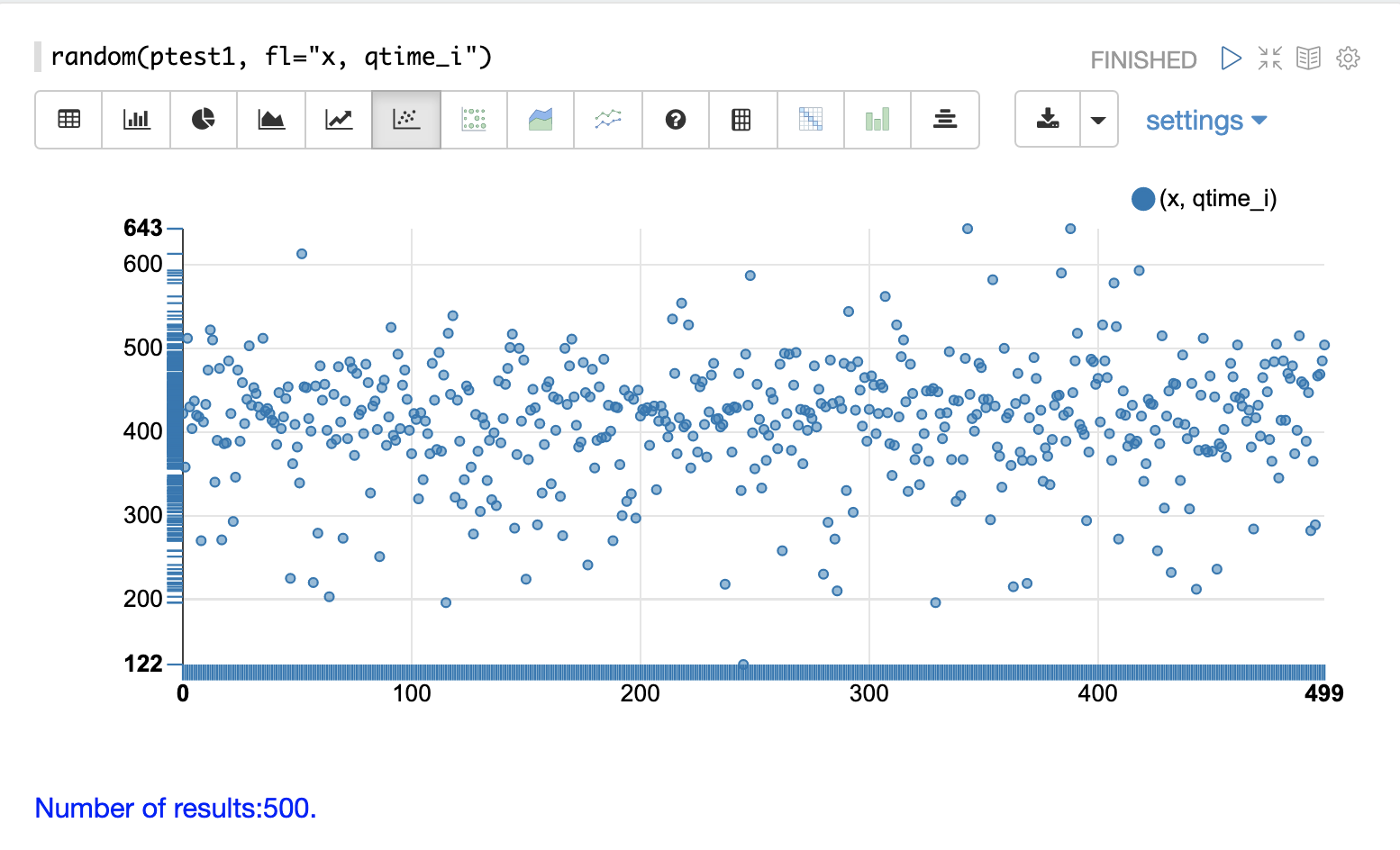
从这个散点图我们可以了解关于查询时间的一些重要信息
-
样本查询时间范围从最低的 122 到最高的 643。
-
平均值似乎略高于 400 毫秒。
-
查询时间往往更靠近平均值聚集,并且随着它们远离平均值,它们变得不那么频繁。
最高 QTime 散点图
可视化日志数据中记录的最高查询时间通常很有用。这可以通过使用 search 函数并按 qtime_i desc 排序来完成。
在下面的示例中,search 函数返回 ptest1 集合中最高的 500 个查询时间,并将结果设置为变量 a。然后,使用 col 函数从结果集中提取 qtime_i 列到向量中,并将其设置为变量 y。
然后使用 zplot 函数在散点图的 y 轴上绘制查询时间。
使用 rev 函数反转查询时间向量,以便可视化显示从最低到最高的查询时间。 |
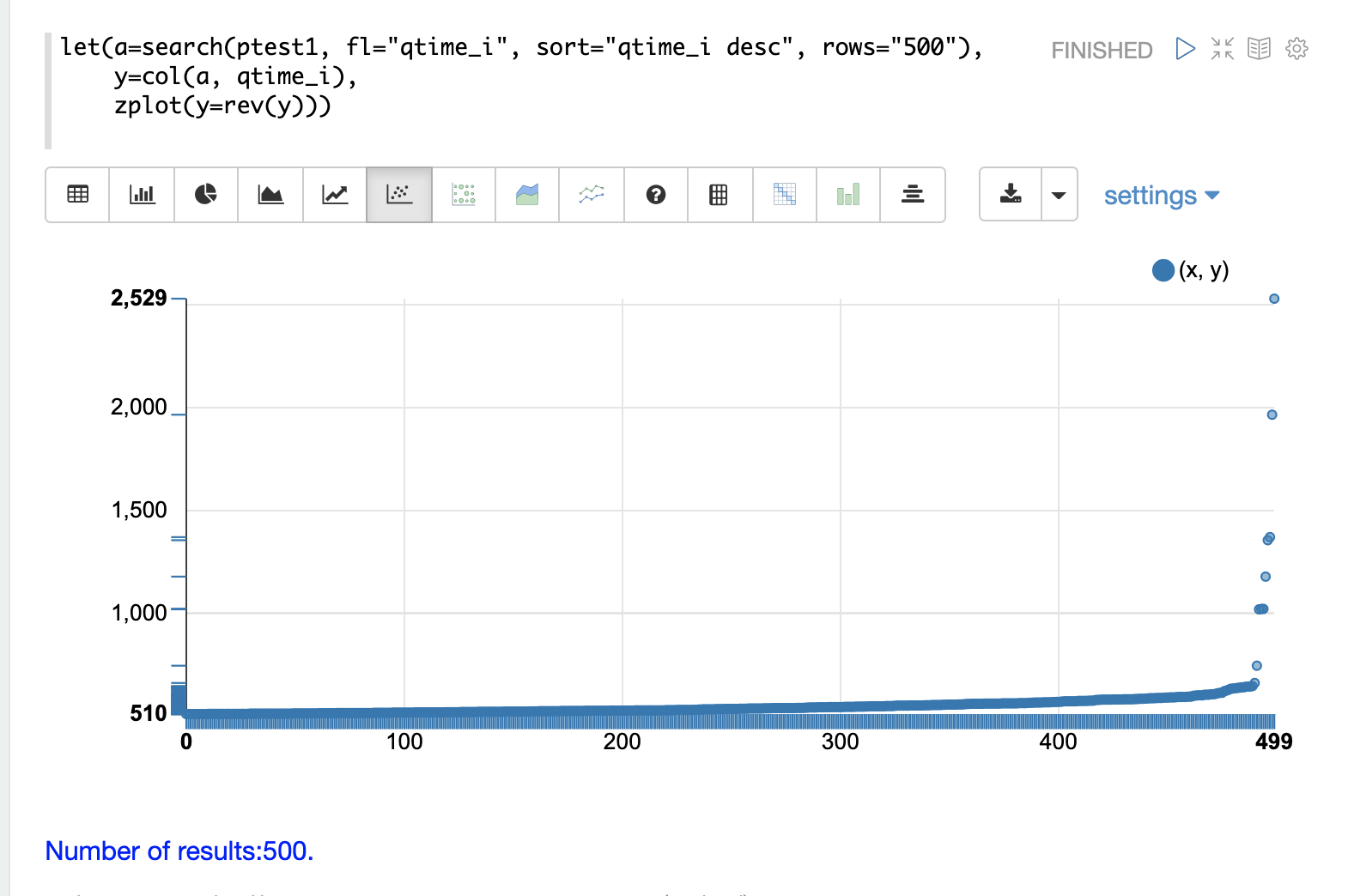
从这个图中我们可以看到,最高的 500 个查询时间从 510 毫秒开始,缓慢上升,直到最后 10 个向上飙升,最终达到最高查询时间 2529 毫秒。
QTime 分布
在此示例中,创建了一个可视化,显示了四舍五入到最接近秒的查询时间分布。
下面的示例首先抽取 10000 条具有 type_s* 为 query 的日志记录的随机样本。random 函数的结果被分配给变量 a。
然后使用 col 函数从结果中提取 qtime_i 字段。查询时间的向量设置为变量 b。
然后使用 scalarDivide 函数将查询时间向量的所有元素除以 1000。这会将查询时间从毫秒转换为秒。结果设置为变量 c。
然后,round 函数将查询时间向量的所有元素四舍五入到最接近的秒。这意味着所有小于 500 毫秒的查询时间都将四舍五入为 0。
然后将 freqTable 函数应用于四舍五入到最接近秒的查询时间向量。
结果频率表显示在下面的可视化中。x 轴是秒数。y 轴是四舍五入到每秒的查询次数。
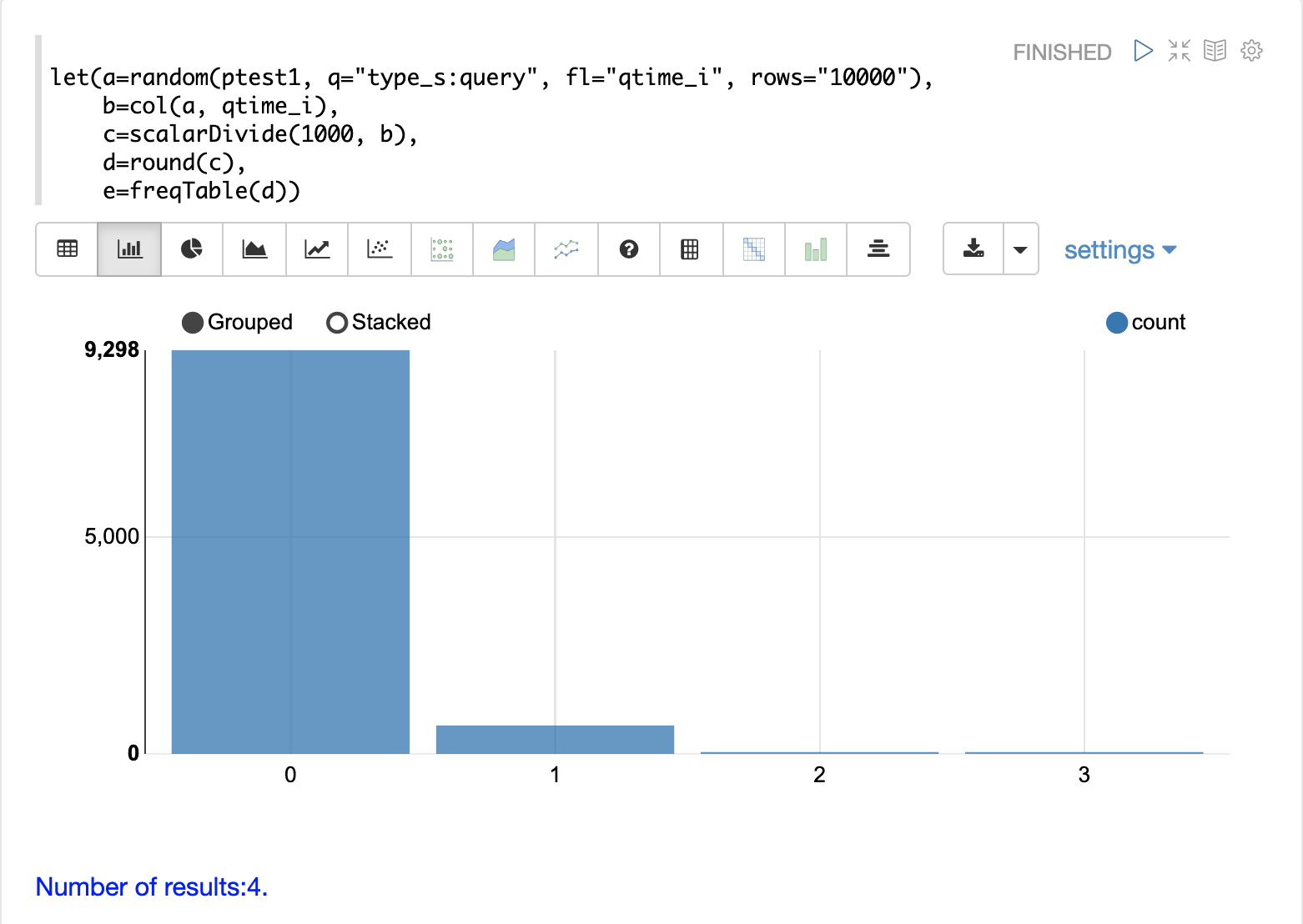
请注意,大约 93% 的查询时间四舍五入为 0,这意味着它们低于 500 毫秒。大约 6% 四舍五入为 1,其余的四舍五入为 2 或 3 秒。
QTime 百分位数图
百分位数图是理解日志中查询时间分布的另一个强大工具。下面的示例演示了如何创建和解释百分位数图。
在此示例中,创建了一个百分位数 array 并将其设置为变量 p。
然后抽取 10000 条日志记录的随机样本,并将其设置为变量 a。然后使用 col 函数从样本结果中提取 qtime_i 字段,并将此向量设置为变量 b。
然后使用 percentile 函数计算查询时间向量中每个百分位数的值。设置为变量 p 的百分位数数组会告诉 percentile 函数要计算哪些百分位数。
然后使用 zplot 函数在 x 轴上绘制 百分位数,在 y 轴上绘制每个百分位数的 查询时间。
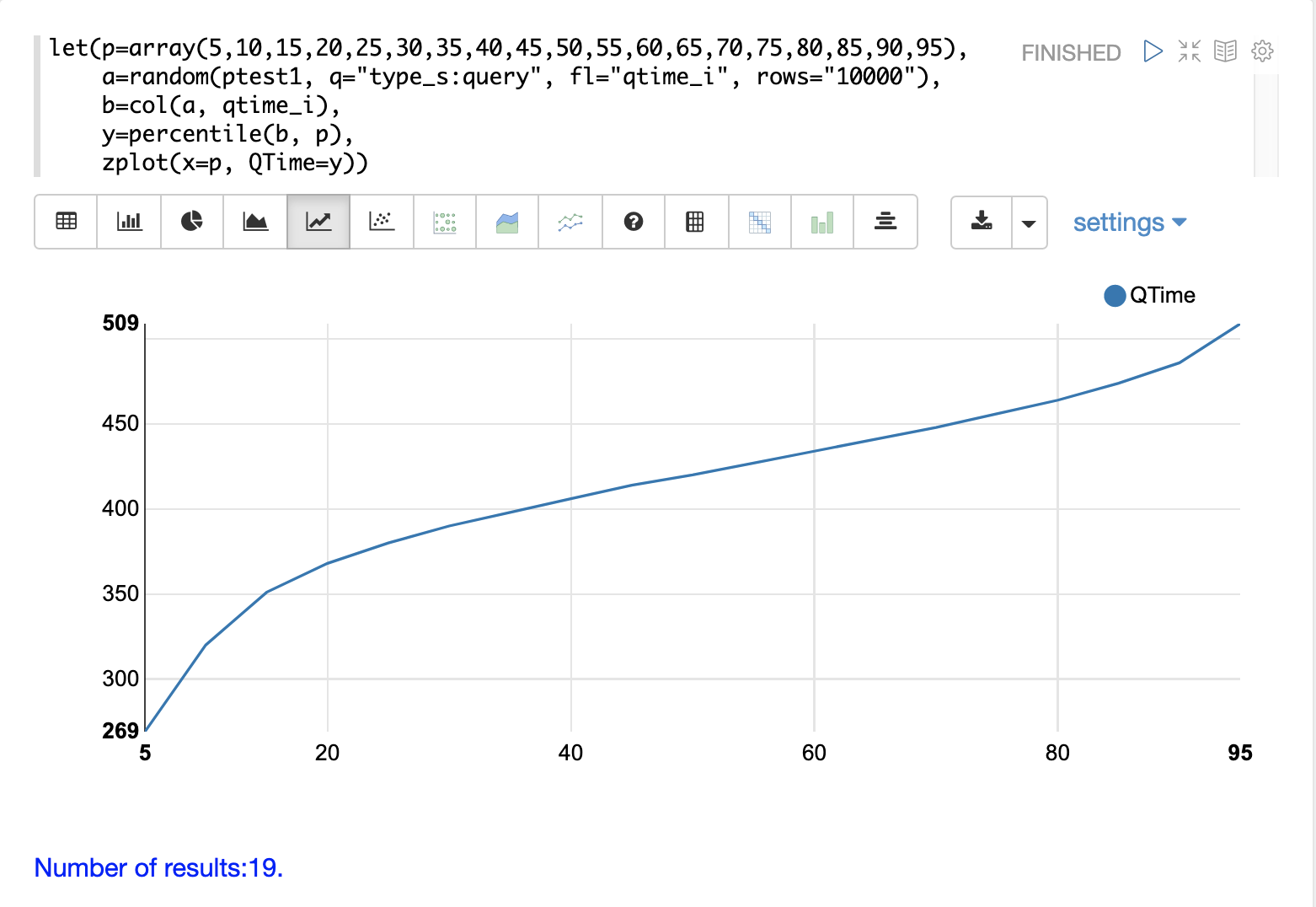
从图中我们可以看到,第 80 个百分位数的查询时间为 464 毫秒。这意味着 80% 的查询低于 464 毫秒。
性能故障排除
如果查询分析确定查询未按预期执行,则日志分析也可用于排除速度缓慢的原因。以下部分演示了用于查找查询速度缓慢的来源的几种方法。
慢节点
在分布式搜索中,最终搜索性能仅与集群中最慢响应的分片一样快。因此,一个慢节点可能导致整体搜索时间慢。
日志记录中提供了 core_s、replica_s 和 shard_s 字段。这些字段允许按 核心、副本 或 分片 计算平均查询时间。
core_s 字段特别有用,因为它是最细粒度的元素,并且命名约定通常包括集合、分片和副本信息。
下面的示例使用 facet 函数按核心计算 avg(qtime_i)。
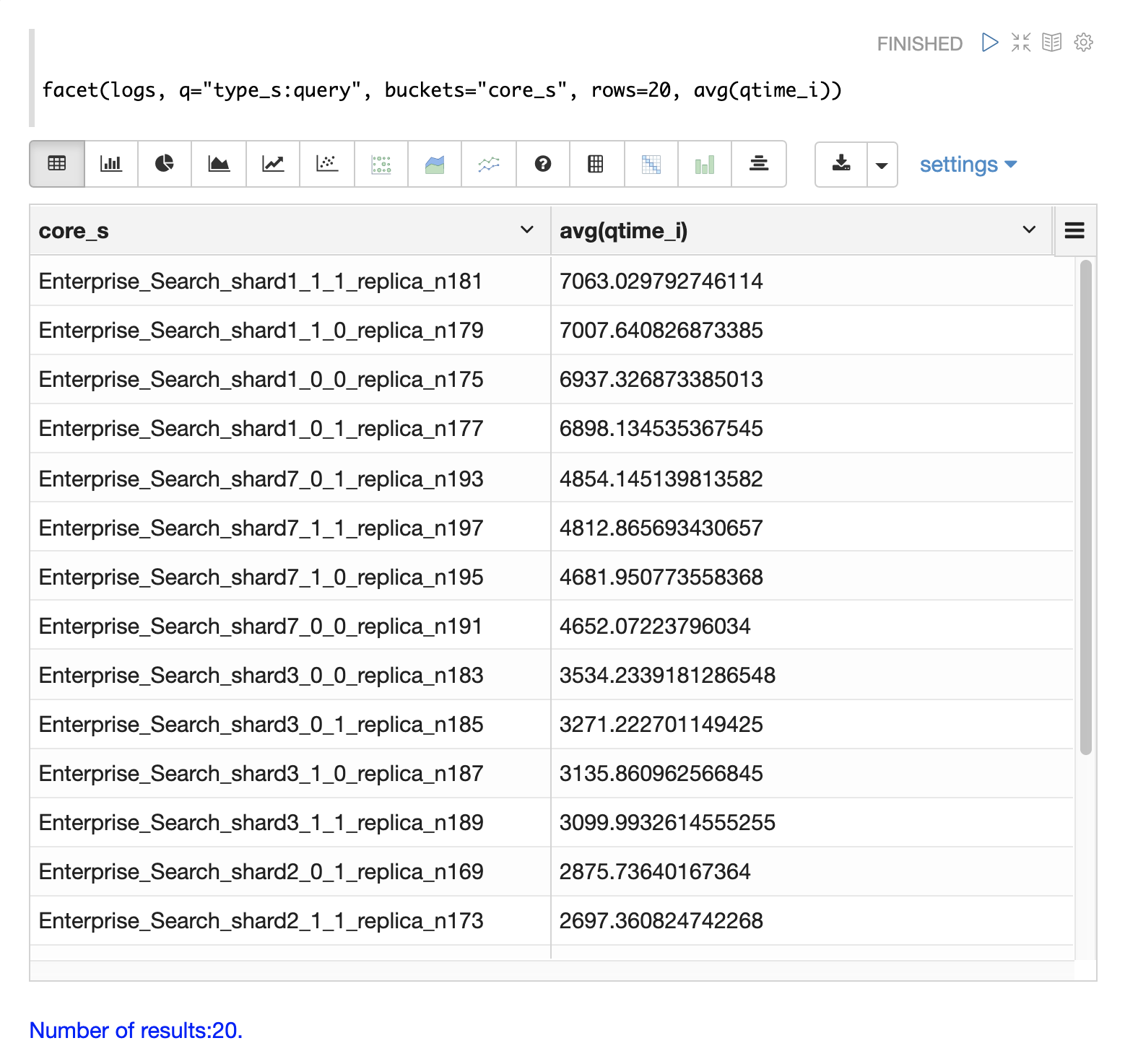
请注意,在结果中,core_s 字段包含有关 集合、分片 和 副本 的信息。该示例还显示,同一集合中某些核心的 qtime 似乎明显更高。这应该触发对为什么这些核心的性能可能较慢的更深入调查。
慢查询
如果查询分析显示大多数查询执行良好,但存在执行缓慢的异常查询,则其中一个原因可能是特定查询执行缓慢。
q_s 和 q_t 字段都保存来自 Solr 请求的 q 参数的值。q_s 字段是一个字符串字段,而 q_t 字段已被标记化。
可以使用 search 函数通过按 qtime_i desc 对结果进行排序来返回日志中 N 个最慢的查询。下面的示例演示了这一点
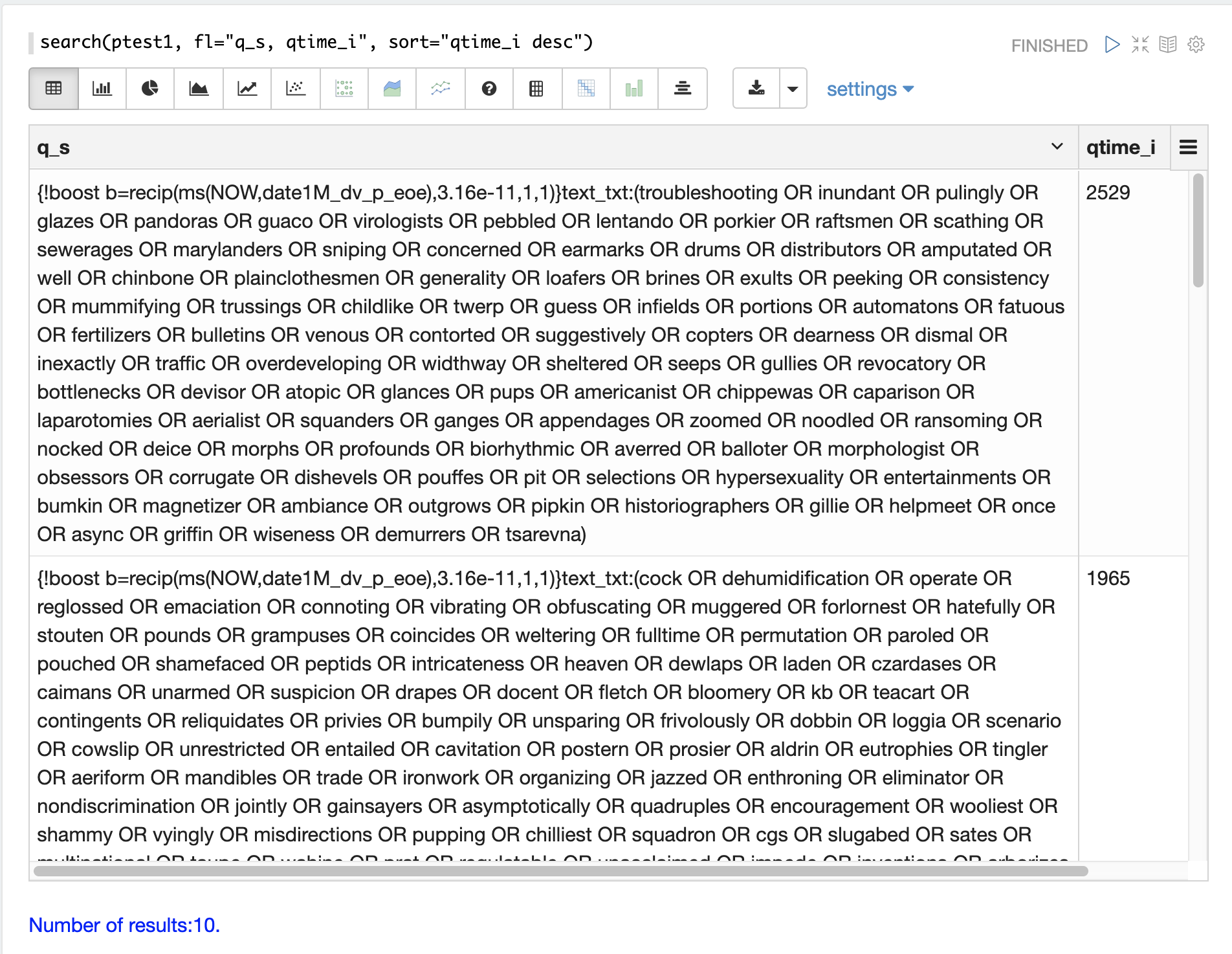
检索到查询后,可以单独检查和尝试它们,以确定查询是否始终缓慢。如果查询被证明是缓慢的,则可以制定一个改进查询性能的计划。
提交
提交和导致提交的活动(例如完整索引复制)可能会导致查询性能降低。时间序列可视化可以帮助确定提交是否与性能下降有关。
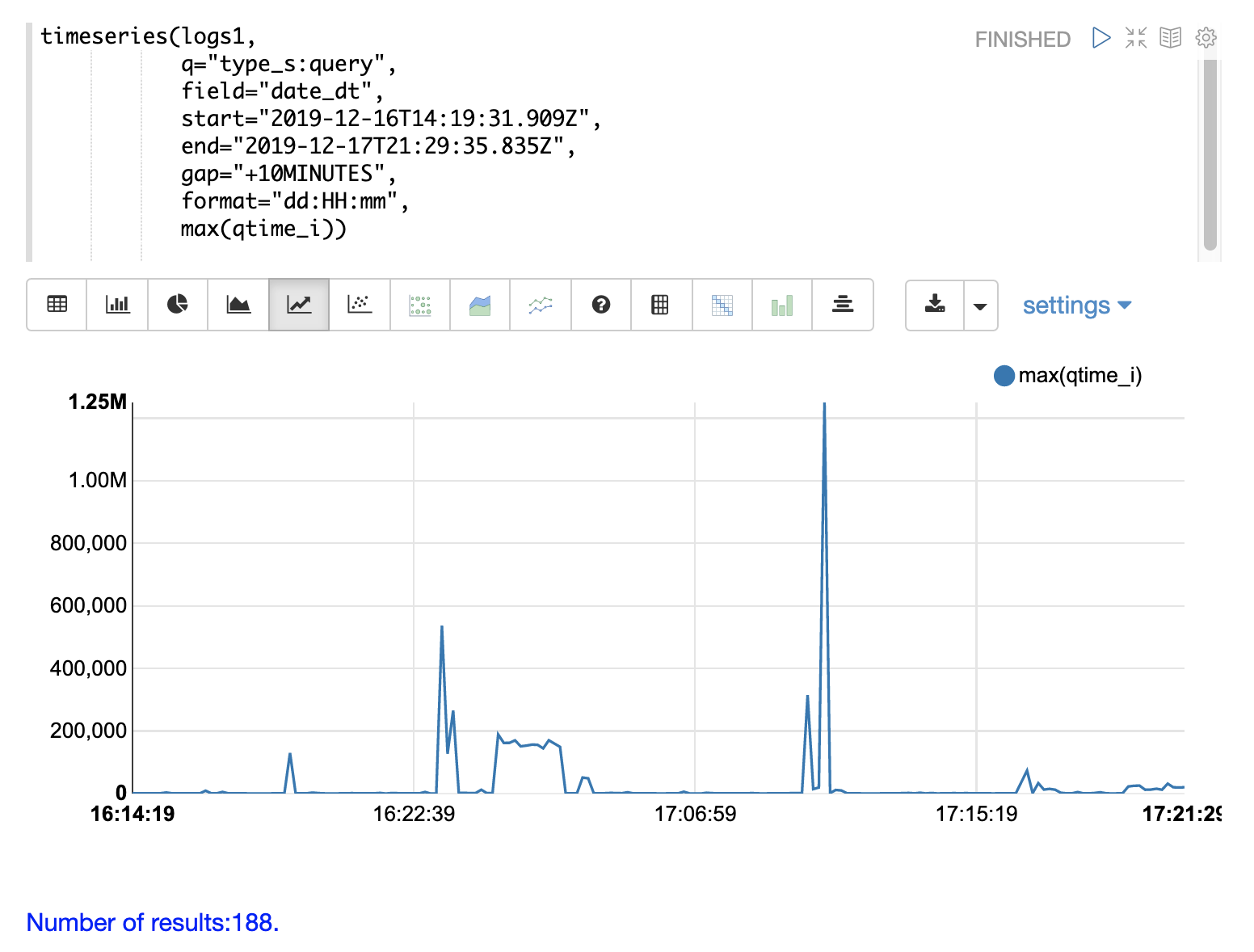
第一步是可视化查询性能问题。下面的时间序列将日志结果限制为类型为 query 的记录,并计算十分钟间隔的 max(qtime_i)。该图在 x 轴上显示日期、小时和分钟,在 y 轴上显示以毫秒为单位的 max(qtime_i)。请注意,max qtime_i 中存在一些需要理解的极端峰值。
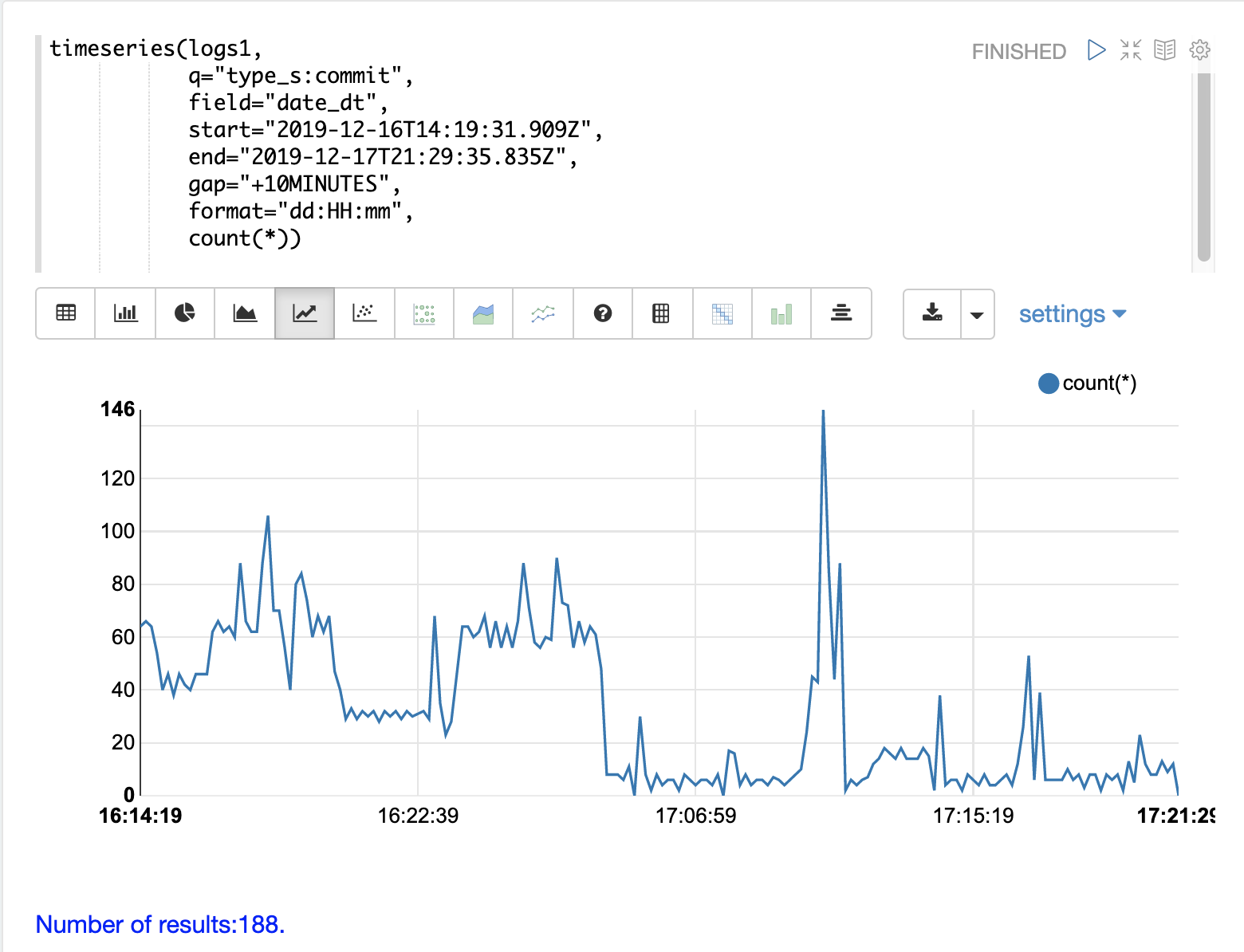
下一步是生成一个时间序列,计算相同时间间隔内的提交次数。下面的时间序列使用与初始时间序列相同的 start、end 和 gap。但是,此时间序列是针对类型为 commit 的记录计算的。计算提交的计数并将其绘制在 y 轴上。
请注意,在 max qtime_i 中的峰值附近出现提交活动的峰值。
最后一步是将两个时间序列叠加在同一张图中。
这是通过执行时间序列分析并将结果赋值给变量来实现的,在本例中为 a 和 b。
然后,使用 col 函数从第一个时间序列中提取 date_dt 和 max(qtime_i) 字段作为向量,并将其赋值给变量。同时,从第二个时间序列中提取 count(*) 字段。
接着使用 zplot 函数将时间戳向量绘制在 x 轴上,并将最大 qtimes 和提交计数向量绘制在 y 轴上。
minMaxScale 函数用于将两个向量缩放到 0 到 1 之间,以便可以在同一图表上进行视觉比较。 |
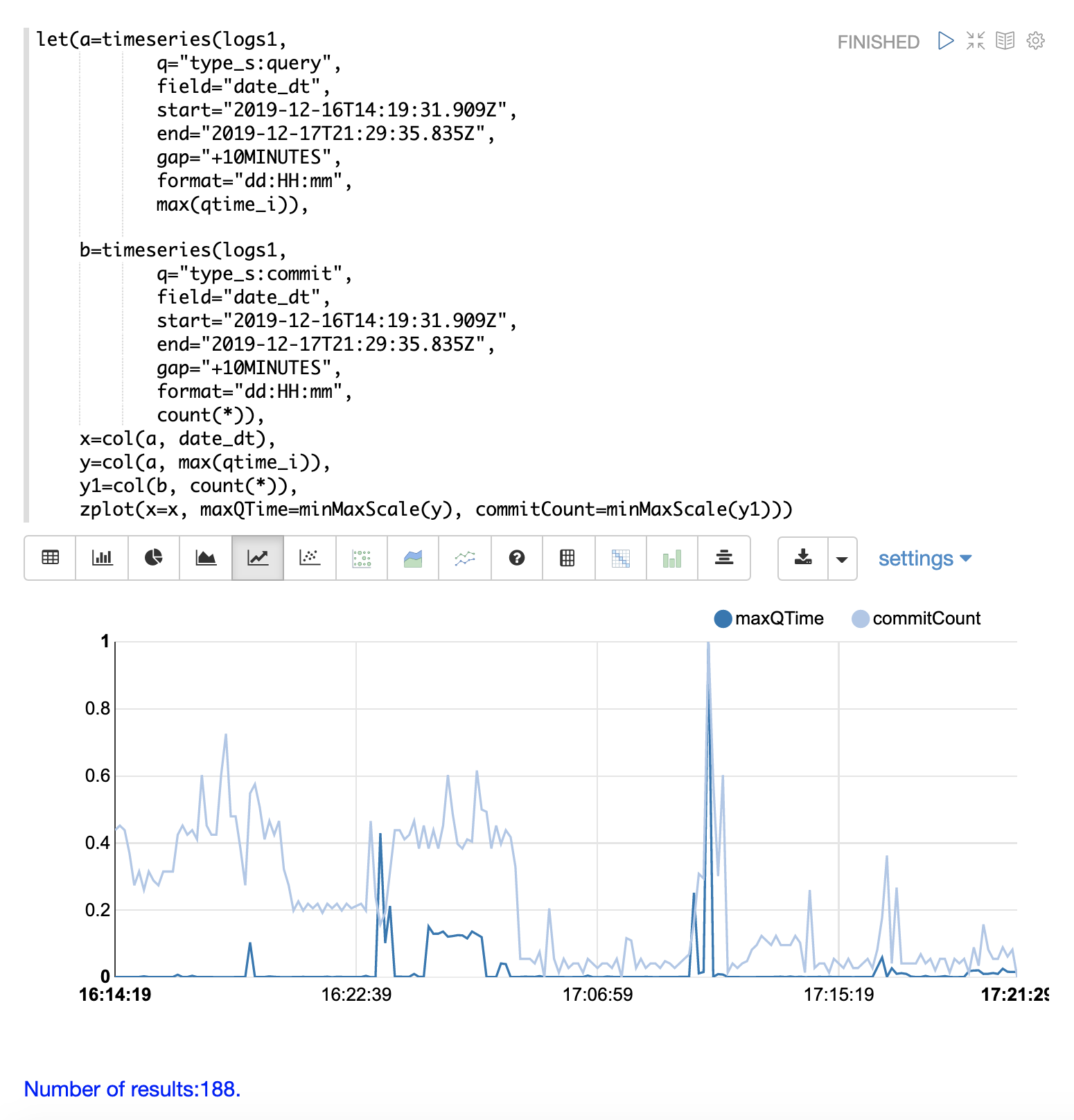
请注意,在此图中,提交计数似乎与最大 qtime_i 的峰值密切相关。